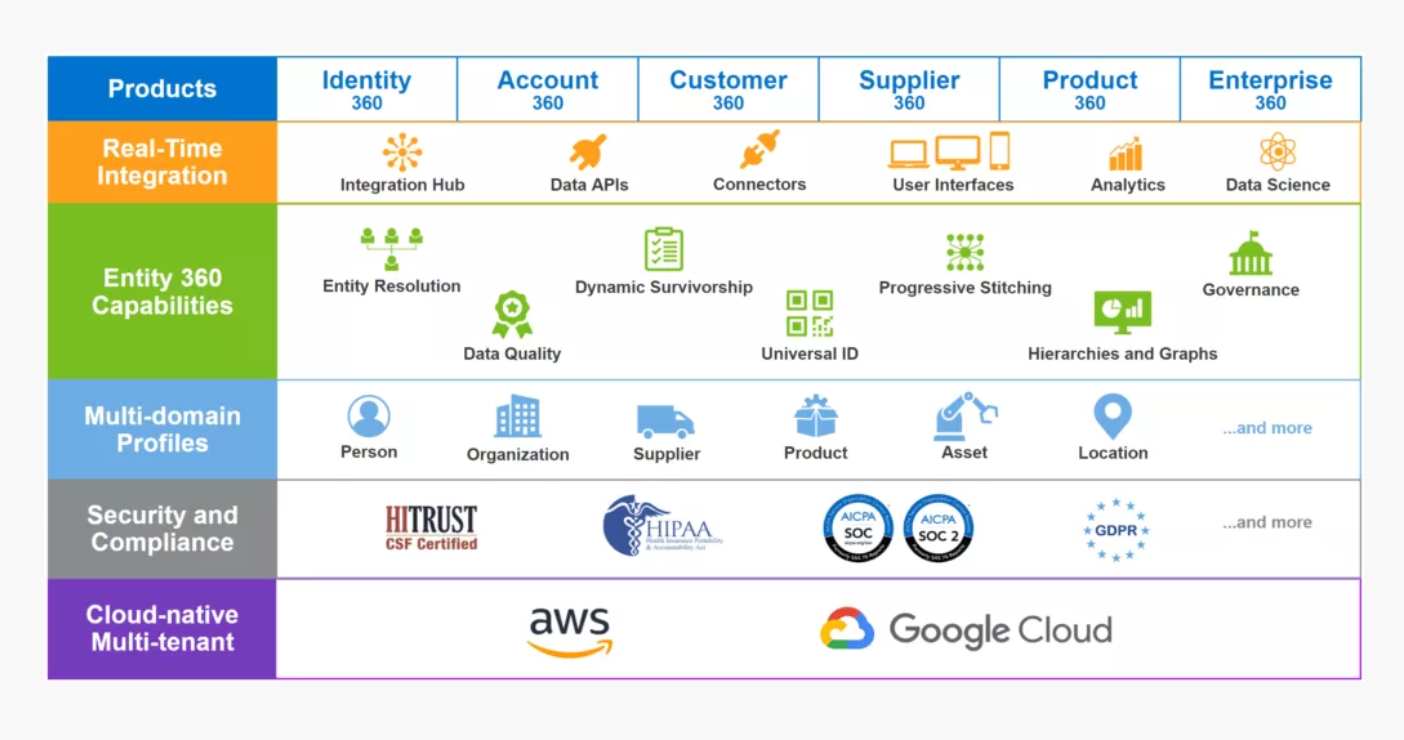
Today it is time to present the fourth vendor to be on The Disruptive MDM / PIM / DQM List in 2022. That is Reltio.
I have been following Reltio here on the blog since 2013 as this MDM vendor has grown from an entrepreneur to a recognized solution provider recently manifested as being a leader in the Forrester MDM Wave and receiving 120 M USD in funding last month.
Reltio is a multi-domain cloud-native MDM solution covering a broad range of MDM capabilities.
One of the recurring entries on The Disruptive MDM/PIM/DQM List is Contentserv.
Contentserv operates under the slogan: Futurize your customers’ product experience.
Using Contentserv, you will be able to develop the groundbreaking product experiences your customers expect — across multiple channels. Contentserv help you unleash the potential of your product information, using our unique combination of advanced technologies.
Contetserv has combined multiple data management technologies in a single platform for controlling the total product experience. The platform facilitates collecting data from suppliers, enriching it into high-grade content, and then personalizing it for use in targeted marketing and promotions.
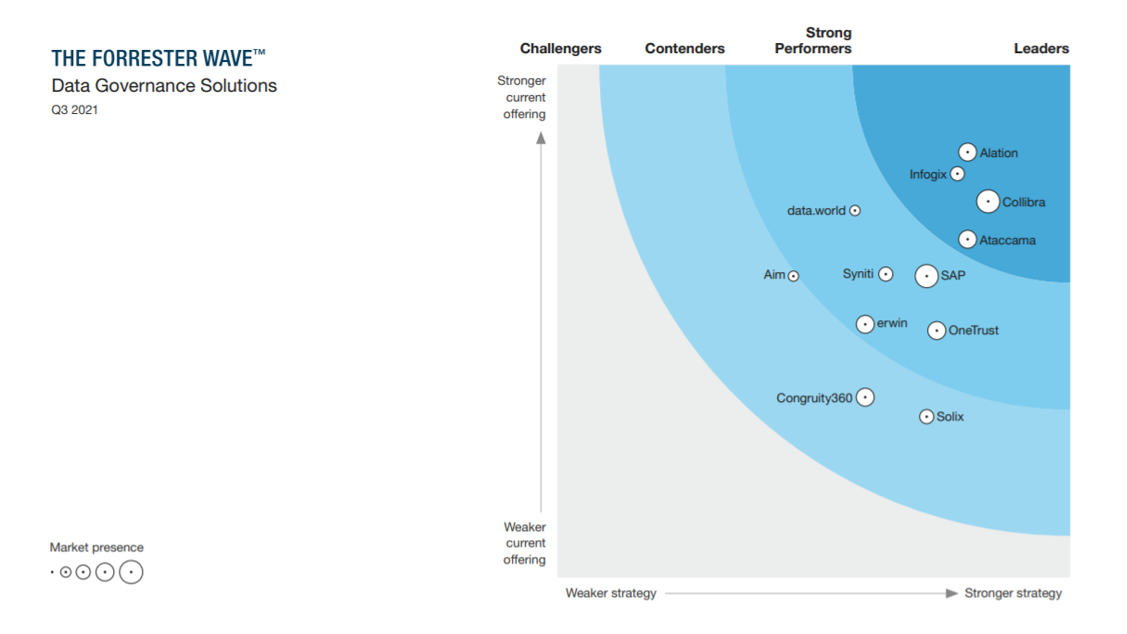
Solutions for data governance are still rare. However, more and more organizations are looking for the technology part of the data governance discipline to underpin the else predominant people and process part of this challenge.
The Forrester Data Governance Wave 2021 is a list of solutions for data governance. As rightfully stated in the report: “Organizations have an ever-increasing appetite to leverage their data for business advantage, either through internal collaboration, data sharing across ecosystems, direct commercialization, or as the basis for AI-driven business decision-making. While doing so, organizations must take care to maintain employee, partner, and customer trust in their approach of leveraging data (and technology fueled by data). This requires data governance and data governance solutions to step up once again and enable data-driven businesses to leverage their data responsibly, ethically, compliantly, and accountably.”
The wave looks like this:
The solutions included seems to be a mix of data governance pure players, data privacy and data protection specialists and more general data management solution providers.
Erwin has been better known for their data modelling technology, which they still do also.
Ataccama is also a recognized MDM and Data Quality Tool vendor.
Not surprisingly Informatica is missing from the list as Informatica and Forrester seem to have dysfunctional relationship. I think the list is incomplete without Informatica – and IBM as well, though they do all the other data management stuff too. Like SAP who is in there.
You can, against your Personal Identifiable Information, get a free copy of the report from Ataccama here.
The previous acquisitions have strengthened the Precisely offerings around data quality for the customer master data domain and the adjacent location domain.
The Winshuttle take over will make Precisely a multidomain vendor adding cross domain capabilities and specific product domain capabilities.
The original Winshuttle capabilities revolves around process automation for predominately SAP environments covering all master data domains and further Application Data Management (ADM).
As Winshuttle recently took over the Product Information Management (PIM) solution provider Enterworks, this will bring capabilities around product master data management and thus make Precisely a provider for a broad spectrum of master data domains.
The interesting question will be in what degree Precisely over the time will be willing to and able to integrate these different solutions so a one-stop-shopping experience will become a one-stop digital experience for their clients.
The methodology and lingo differ a bit, however the ranking is, as with all these kinds of analyst rankings, based on that the vendors are assessed more positive the closer they are to the top right corner.
The two analyst firms are in more or less agreement about some vendors while some vendors are assessed quite different. These are in particular:
Informatica, who is assessed much more negative by Forrester than by Ventana. It is a part of the story that Informatica for a long time has declined to participate in Forrester’s PIM assessments.
Akeneo, who is a new vendor among the major players, and has a better debut at Ventana than at Forrester.
Stibo Systems, who has been a leader at Forrester for some years but has moved down to a modest position at Ventana in the latest ranking.
Looking at assessing the vendors against the others is close to me as part of the Select Your Solution service on The Disruptive MDM / PIM / DQM List. Here the assessment is based on the actual context, scope and requirements for you as a potential buyer (or someone who is helping a potential buyer). When doing that it is natural that a given vendor can be closest to the top right corner in some cases and not in other cases.
That analysts in a generic ranking reaches a different result only underpins that solution selection is not easy and requires a substantial knowledge about the available solutions, where they come from and where they are heading.
If you need help navigating in this jungle, ping me here:
Analyst firms occasionally publish market reports with a generic solution overview for Master Data Management (MDM), Product Information Management (PIM) and Data Quality Management (DQM).
You can get a free ranking that also include the rising stars on the solution market and is based on your context, scope and requirements here.
You can book a free short online meeting with me for further discussion on your business case as part of my engagement at the consultancy firm Astrocytia here.
From time to time, analyst firms publish market reports that include their opinion and ranking of the vendors/solution providers in a specific market, such as Master Data Management (MDM).
Reading such reports, it strikes me that the rankings often do not seem to be in line with what is going in the market, especially when you consider market positioning, demand and technological developments.
One example was touched on in my post “The Latest Constellation Research MDM Shortlist” where the analyst firm in question seemed to take a long time to understand that Oracle had left the MDM market.
Gartner’s Magic Quadrant reports are generally the most popular; their rankings often appear in corporate PowerPoint decks when businesses want to evaluate and select the right MDM solution that fits their needs. And yet, I would argue that Gartner is more conservative in its approach. For example, it took Gartner a long time to abandon the notion that there was a separate customer MDM and product MDM enterprise-level market, as I examined in my post “Who will become Future Leaders in the Gartner Multidomain MDM Magic Quadrant?”
You’ll notice that the magic quadrant from 2017 had a very limited number of market players on it; it excluded several vendors who offer MDM via cloud subscription models who are now recognised as key players and who, in hindsight, should have been included on many shortlists back then.
So, when the next Gartner Magic Quadrant for MDM is published (currently scheduled for the end of November 2020, though I hear it may be pushed to January 2021), I would always recommend you take a look at who is not included as well as those who are, and ask yourself what information has led Gartner to rank the vendors the way they have.
In that sense, Gartner’s thoroughness can often work against them as a lot of the data used in the upcoming report will be from 2019. Also, you should be aware that customer feedback is given by those who made the decision to implement a specific solution; I often hear a number of differing opinions from people across a business when they evaluate MDM solutions.
It’s also interesting to note how analyst firms differ between them. Examples from the world of MDM include a dysfunctional relationship between Forrester and Informatica as well as between Gartner and IBM, and how Forrester, opposed to Gartner, has a much more favourable assessment of a new kind of MDM provider like Reltio.
Disclosure: I recently worked with Reltio on a webinar and a white paper.
Generic rankings of vendors on a market, like the Master Data Management (MDM) market, are in my eyes not very useful.
So, it is relieving that the recent Now Tech report format from Forrester does not do that.
The Now Tech: Master Data Management, Q4 2020 from Forrester was published last month. In here the vendors are grouped by size and some key selection criteria are stated for each vendor. This include:
Deployment mode which in Forrester lingo are functional segments covering public cloud, multi-cloud, on-premise and SaaS.
Geographic segments with percentage of revenue for North America, Latin America, EMEA (Europe/ Middle East/Africa) and APAC (Asia/Pacific).
Vertical market focus and sample customers.
You can access the report if you are a Forrester client or buy it from Forrester. Alternatively, you can have a free copy at the Prospecta site, as the MDO (Master Data Online) solution from Prospecta is included in the report. Link here.
Analyst firms occasionally publish market reports with a generic solution overview for Master Data Management (MDM), Product Information Management (PIM) and Data Quality Management (DQM).
You can get a free ranking that also include the rising stars on the solution market and is based on your context, scope and requirements here.
You can book a free short online meeting with me for further discussion on your business case as part of my engagement at the consultancy firm Astrocytia here.