Data Matching is the discipline within data quality management where you deal with the probably most frequent data quality issue that you meet in almost every organization, which is duplicates in master data. This is duplicates in customer master data, duplicates in supplier master data, duplicates in combined / other business partner master data, duplicates in product master data and duplicates in other master data repositories.
A duplicate (or duplicate group) is where two (or more) records in a system or across multiple systems represent the same real-world entity.
Typically, you can use a tool to identify these duplicates. It can be as inexpensive as using Excel, it can be a module in a CRM or other application, it can be a capability in a Master Data Management (MDM) platform, or it can be a dedicated Data Quality Management (DQM) solution.
Over the years there have been developed numerous tools and embedded capabilities to tackle the data matching challenge. Some solutions focus on party (customer/supplier) master data and some solutions focus on product master data. Within party master data many solutions focus on person master data. Many solutions are optimized for a given geography or a few major geographies.
In my experience you can classify available tools / capabilities into the below 5 levels of efficiency:
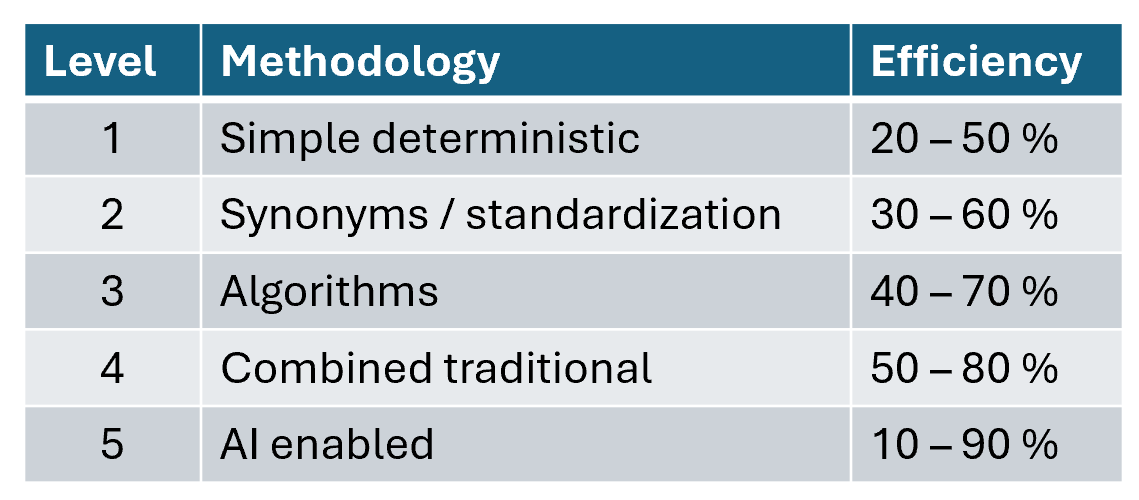
The efficiency percentage here is an empirical measure of the percentage of actual duplicates the solution can identify automatically.
In more detail, the levels are:
1: Simple deterministic
Here you compare exact values between two duplicate candidate records or use simple transformed values as upper-case conversion or simple phonetic codes as for example soundex.
Don’t expect to catch every duplicate using this approach. If you have good, standardized master data 50 % is achievable. However, with a normal cleanliness, it will be lower.
Surprisingly many organizations still start here as a first step of reinventing the wheel in a Do-It-Yourself (DIY) approach.
2: Synonyms / standardization
In this more comprehensive approach you can replace, substitute, or remove values or words in values based on synonym lists. Examples are replacing person nicknames with guessed formal names, replacing common abbreviations in street names with a standardized term and removing legal forms in company names.
Enrichment / verification with external data can also be used, for example by standardizing addresses or classifying products.
3: Algorithms
Here you will use an algorithm as part of the comparison. Edit distance algorithms, as we know from autocorrection, are popular here. One frequently used one is the Levenshtein distance algorithm. But there are plenty out there to choose from each with their pros and cons.
Many data matching tools simply let you choose from using one of these algorithms in each scenario.
4: Combined traditional
If your DIY approach didn’t stop when encompassing more and
more synonyms it will probably be here where you realize that further quest for
raising efficiency includes combining several methodologies and doing dynamic
combined algorithm utilization.
A minor selection of commercial data matching tools and
embedded capabilities can do that for you so you avoid reinventing the wheel
one more time.
This will yield high efficiency, but not perfection.
5: AI Enabled
Using Artificial Intelligence (AI) in data matching has been practiced for decades as told in the post The Art in Data Matching. With the general rise of AI in recent years there is renewed interest both at tool vendors and at users of data matching to industrialize this.
The results are still sparse out there. With limited training of models, it can be less efficient than traditional methodology. However, it can for sure also limit the gap between traditional efficiency and perfection.
More on Data Matching
There is of course much more to data matching than comparing duplicate candidates. Learn some more about The Art of Data Matching.
And, what to do when a duplicate is identified is a new story. This is examined in the post Three Master Data Survivorship Approaches.





 Product Golden Record
Product Golden Record
 Two of the most addressed data management topics on this blog is data matching and multidomain Master Data Management (MDM). In addition, I have also founded two LinkedIn Groups for people interested in one of or both topics.
Two of the most addressed data management topics on this blog is data matching and multidomain Master Data Management (MDM). In addition, I have also founded two LinkedIn Groups for people interested in one of or both topics. The Multi-Domain MDM Group has close to 2,500 members. In here we exchange knowledge on how to encompass more than a single master data domain in an MDM initiative. In that way the group also covers the evolution of MDM as the discipline – and solutions – has emerged from Customer Data Integration (CDI) and Product Information Management (PIM).
The Multi-Domain MDM Group has close to 2,500 members. In here we exchange knowledge on how to encompass more than a single master data domain in an MDM initiative. In that way the group also covers the evolution of MDM as the discipline – and solutions – has emerged from Customer Data Integration (CDI) and Product Information Management (PIM).


