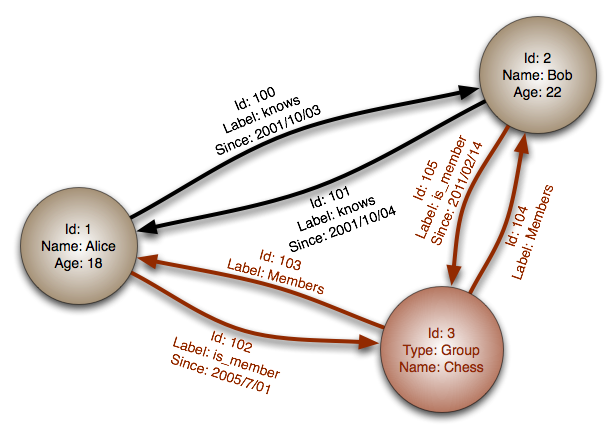
A core intersection between Data Quality Management (DQM) and Master Data Management (MDM) is deduplication. The process here will basically involve:
- Match master data records across the enterprise application landscape, where these records describe the same real-world entity most frequently being a person, organization, product or asset.
- Link the master data records in the best fit / achievable way, for example as a golden record.
- Apply the master data records / golden record to a hierarchy.
Data Matching
The classic data matching quest is to identify data records that refer to the same person being an existing customer and/or prospective customer. The first solutions for doing that emerged more than 40 years ago. Since then the more difficult task of identifying the same organization being a customer, prospective customer, vendor/supplier or other business partner has been implemented while also solutions for identifying products as being the same have been deployed.
Besides using data matching to detect internal duplicates within an enterprise, data matching has also been used to match against external registries. Doing this serves as a mean to enrich internal records while this also helps in identifying internal duplicates.
Master Data Survivorship
When two or more data records have been confirmed as duplicates there are various ways to deal with the result.
In the registry MDM style, you will only store the IDs between the linked records so the linkage can be used for specific operational and analytic purposes in source and target applications.
Further, there are more advanced ways of using the linkage as described in the post Three Master Data Survivorship Approaches.

One relatively simple approach is to choose the best fit record as the survivor in the MDM hub and then keep the IDs of the MDM purged records as a link back to the sourced application records.
The probably most used approach is to form a golden record from the best fit data elements, store this compiled record in the MDM hub and keep the IDs of the linked records from the sourced applications.
A third way is to keep the sourced records in the MDM hub and on the fly compile a golden view for a given purpose.
Hierarchy Management
When you inspect records identified as a duplicate candidate, you will often have to decide if they describe the same real-world entity or if they describe two real-world entities belonging to the same hierarchy.
Instead of throwing away the latter result, this link can be stored in the MDM hub as well as a relation in a hierarchy (or graph) and thus support a broader range of operational and analytic purposes.
The main hierarchies in play here are described in the post Are These Familiar Hierarchies in Your MDM / PIM / DQM Solution?

With persons in private roles a classic challenge is to distinguish between the individual person, a household with a shared economy and people who happen to live at the same postal address. The location hierarchy plays a role in solving this case. This quest includes having precise addresses when identifying units in large buildings and knowing the kind of building. The probability of two John Smith records being the same person differs if it is a single-family house address or the address of a nursing home.
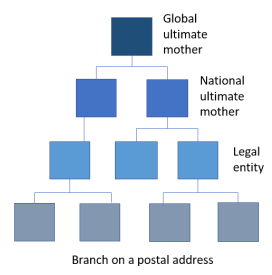
Organizations can belong to a company family tree. A basic representation for example used in the Dun & Bradstreet Worldbase is having branches at a postal address. These branches belong a legal entity with a headquarter at a given postal address, where there may be other individual branches too. Each legal entity in an enterprise may have a national ultimate mother. In multinational enterprises, there is a global ultimate mother. Public organizations have similar often very complex trees.

Products are also formed in hierarchies. The challenge is to identify if a given product record points to a certain level in the bottom part of a given product hierarchy. Products can have variants in size, colour and more. A product can be packed in different ways. The most prominent product identifier is the Global Trade Identification Number (GTIN) which occur in various representations as for example the Universal Product Code (UPC) popular in North America and European (now International) Article Number (EAN) popular in Europe. These identifiers are applied by each producer (and in some cases distributor) at the product packing variant level.
Solutions Available
When looking for a solution to support you in this conundrum the best fit for you may be a best-of-breed Data Quality Management (DQM) tool and/or a capable Master Data Management (MDM) platform.
This Disruptive MDM / PIM /DQM List has the most innovative candidates here.

 When handling party master data about consumers / citizens we can deal with the basic definition of a family, being a group consisting of two parents and their children living together as a unit.
When handling party master data about consumers / citizens we can deal with the basic definition of a family, being a group consisting of two parents and their children living together as a unit.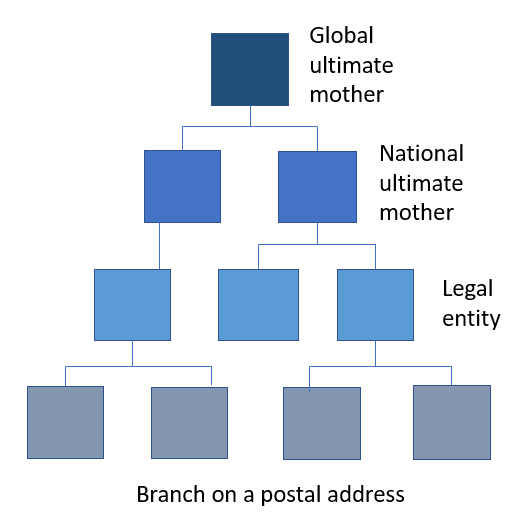 You can build your own company tree describing your customers, suppliers and other business partners. Alternatively or supplementary, you can rely on third party business directories. It is here worth noticing that a national source will only go to the ultimate national mother level while a global source can include the global ultimate mother and thus form larger families.
You can build your own company tree describing your customers, suppliers and other business partners. Alternatively or supplementary, you can rely on third party business directories. It is here worth noticing that a national source will only go to the ultimate national mother level while a global source can include the global ultimate mother and thus form larger families.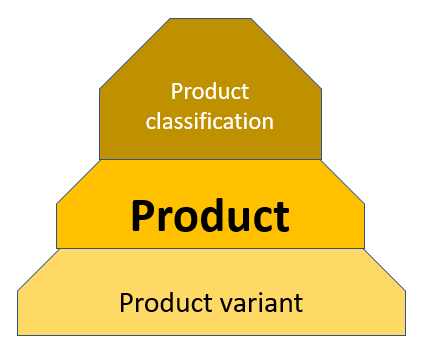 Sometimes it is also used as a term to define a product with a family of variants below, where variants are the same product produced and kept in stock in different colours, sizes and more.
Sometimes it is also used as a term to define a product with a family of variants below, where variants are the same product produced and kept in stock in different colours, sizes and more.
 Today is the first day in the new year. The year of the rooster according to the Lunar Calendar observed in East Asia. One of the characteristics of the year of the rooster is that in this year, people will tend to complicate things.
Today is the first day in the new year. The year of the rooster according to the Lunar Calendar observed in East Asia. One of the characteristics of the year of the rooster is that in this year, people will tend to complicate things.
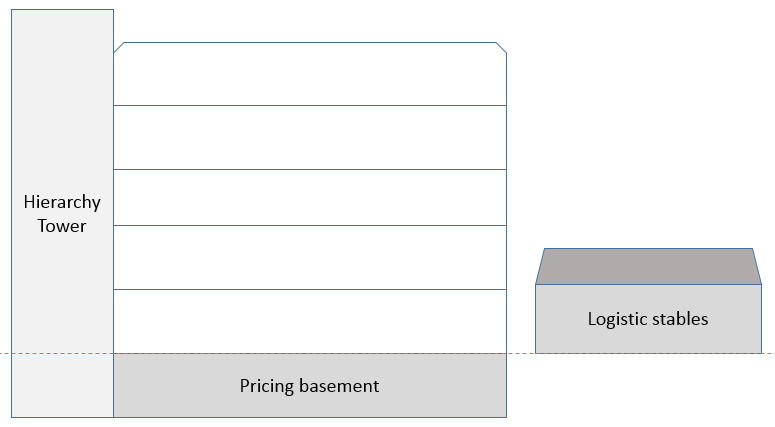
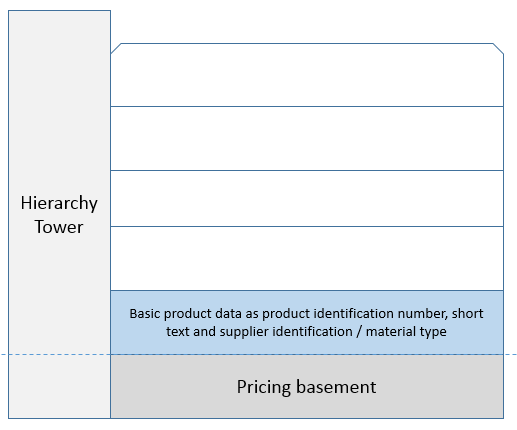
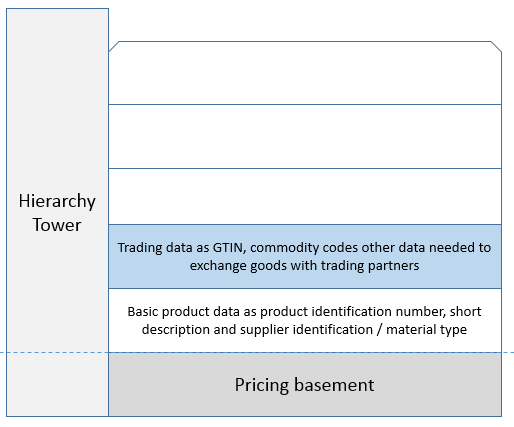

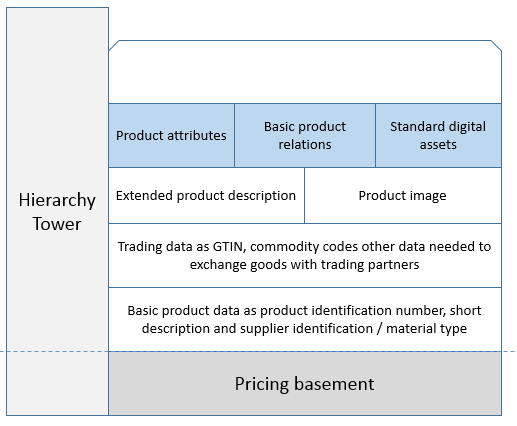


 Using an inheritance approach is a better way. This approach is for product master data based on having a mature hierarchy management in place. When creating a new product you place your product in the hierarchy where it will inherit the attributes common for products on the same branch of the hierarchy and leave it for you to fill in the exact attributes that is specific for the new product. If a new product requires a new branch in the hierarchy, you are forced to think about the common attributes for this branch through.
Using an inheritance approach is a better way. This approach is for product master data based on having a mature hierarchy management in place. When creating a new product you place your product in the hierarchy where it will inherit the attributes common for products on the same branch of the hierarchy and leave it for you to fill in the exact attributes that is specific for the new product. If a new product requires a new branch in the hierarchy, you are forced to think about the common attributes for this branch through.