A recent blog post by Andrew Grill, CEO of Kred, is called Can you spot a social media faker? Fact checking on social media is now becoming even more important.
Besides methods within the social sphere for fact checking, as described in Andrew Grill’s post, I also believe that mashing up social network profiles and traditional external reference data is a great way of getting the full picture.
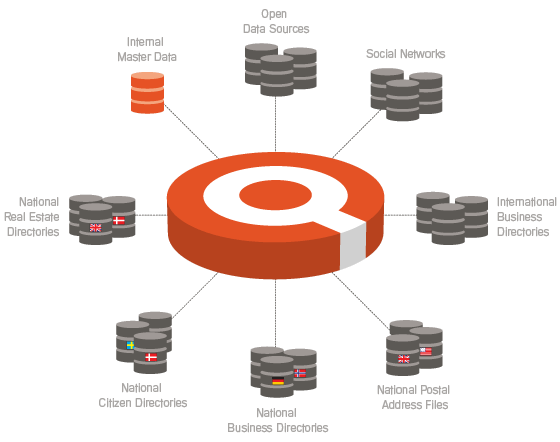
As explained in the post Sharing is the Future of MDM there are several available external options for checking the facts:
- Public sector registries which are getting more and more open being that for example for the address part or even deeper in due respect of privacy considerations which may be different for business entities and individual entities.
- Commercial directories often build on top of public registries.
- Personal data lockers like Mydex
- Social network profiles, including credibility (or influence) services
The challenge is of course that there are plenty of external reference data sources as many sources are national, making up 255 or so variants of each data source, as well as there are plenty of social networks and some credibility (or influence) services for that matter.
Making that easy for you is exactly the concept we are working on in the instant Data Quality, iDQ™, concept.
![]()






