In software architecture, publish–subscribe is a messaging pattern where senders of messages, called publishers, do not program the messages to be sent directly to specific receivers, called subscribers, but instead categorize published messages into classes without knowledge of which subscribers, if any, there may be. Similarly, subscribers express interest in one or more classes and only receive messages that are of interest, without knowledge of which publishers, if any, there are.
This kind of thinking is behind the service called Product Data Lake I am working with now. Whereas a publish-subscribe service is usually something that goes on behind the firewall of an enterprise, Product Data Lake takes this theme into the business ecosystem that exists between trading partners as told in the post Product Data Syndication Freedom.
Therefore, a modification to the publish-subscribe concept in this context is that we actually do make it possible for publishers of product information and subscribers of product information to care a little about who gets and who receives the messages as exemplified in the post Using a Business Entity Identifier from Day One. However, the scheme for that is a modern one resembling a social network where partnerships are requested and accepted/rejected.
As messages between global trading partners can be highly asynchronous and as the taxonomy in use often will be different, there is a storage part in between. How this is implemented is examined in the post Product Data Lake Behind the Scenes.

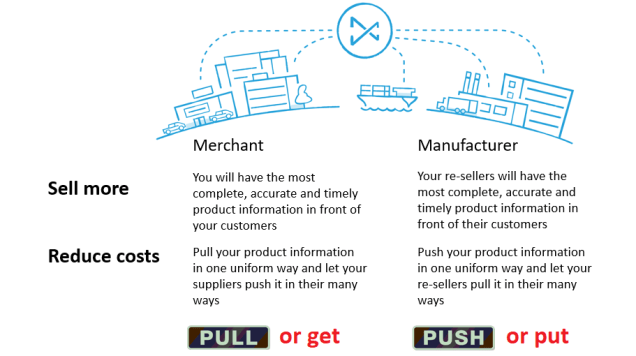
 Much of the talking and doing related to Master Data Management (MDM) today revolves around the master data repository being the central data store for information about customers, suppliers and other parties, products, locations, assets and what else are regarded as master data entities.
Much of the talking and doing related to Master Data Management (MDM) today revolves around the master data repository being the central data store for information about customers, suppliers and other parties, products, locations, assets and what else are regarded as master data entities.




 These statements are in my eyes very true and I guess anyone else will agree.
These statements are in my eyes very true and I guess anyone else will agree. Implementation of such features may be as embedded functionality in CRM and ERP systems or as my favourite term: SOA components. So besides classic data quality elements for monitoring and checking we can add error tolerant search to the component catalogue needed for a good MDM solution.
Implementation of such features may be as embedded functionality in CRM and ERP systems or as my favourite term: SOA components. So besides classic data quality elements for monitoring and checking we can add error tolerant search to the component catalogue needed for a good MDM solution.