If I look at my journey in data quality I think you can say, that I started with working with the good way of implementing data quality tools, then turned to some better ways and, until now at least, is working with the best way of implementing data quality technology.
It is though not that the good old kind of tools are obsolete. They are just relieved from some of the repeating of the hard work in cleaning up dirty data.
The good (old) kind of tools are data cleansing and data matching tools. These tools are good at finding errors in postal addresses, duplicate party records and other nasty stuff in master data. The bad thing about finding the flaws long time after the bad master data has entered the databases, is that it often is very hard to do the corrections after transactions has been related to these master data and that, if you do not fix the root cause, you will have to do this periodically. However, there still are reasons to use these tools as reported in the post Top 5 Reasons for Downstream Cleansing.
The better way is real time validation and correction at data entry where possible. Here a single data element or a range of data elements are checked when entered. For example the address may be checked against reference data, phone number may be checked for adequate format for the country in question or product master data is checked for the right format and against a value list. The hard thing with this is to do it at all entry points. A possible approach to do it is discussed in the post Service Oriented MDM.
The best tools are emphasizing at assisting data capture and thus preventing data quality issues while also making the data capture process more effective by connecting opposite to collecting. Two such tools I have worked with are:
· IDQ™ which is a tool for mashing up internal party master data and 3rd party big reference data sources as explained further in the post instant Single Customer View.
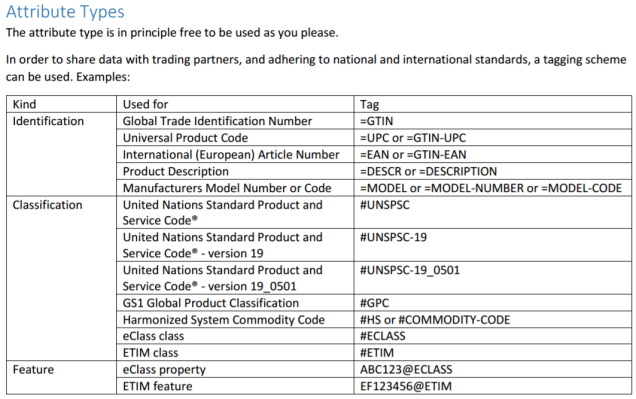
· Product Data Lake, a cloud service for sharing product data in the business ecosystems of manufacturers, distributors, merchants and end users of product information. This service is described in detail here.

 What stroke me the most was however the sharing approach that probably made all the difference in the impact achieved from revealing the core data in the
What stroke me the most was however the sharing approach that probably made all the difference in the impact achieved from revealing the core data in the 
 Using third party data for customer and supplier master data seems to be a very good idea as exemplified in the post
Using third party data for customer and supplier master data seems to be a very good idea as exemplified in the post  When selecting an identifier there are different options as national IDs, LEI, DUNS Number and others as explained in the post
When selecting an identifier there are different options as national IDs, LEI, DUNS Number and others as explained in the post  You may have noticed, that I during the last year have been writing about something called the
You may have noticed, that I during the last year have been writing about something called the 


