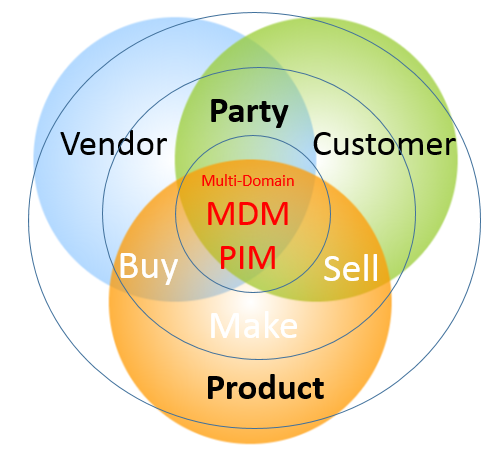
Since the birth of this blog one of the key concepts that has been repeatedly visited is the business partner / party concept in Master Data Management (MDM). This concept is about unifying the handling of data about customers, vendors, contacts, employees and other real-world objects that are all legal entities. One of the first posts from 16 years back was called 360° Business Partner View.
Since then, the uptake for this idea has been greatly helped by all the major ERP vendors over the years, as they have adopted this concept in their newer data models.
This is true for SAP, where the business partner concept was introduced as an option in the old ECC system and now has become the overarching concept is the new S4 system. The concept in S4 is explained by SAP here.
Also, Microsoft has adopted a party concept in their D365 solution. This is explained here.

The Technical Balancing Act
While the data models have been twisted to reflect the business partner / party concept in principle, there are still some halfway solutions in force.
For SAP some examples I have come across are:
- The hierarchy management is for some purposes better suited for the business partner layer and for other purposes better suited for the underlaying customer or vendor layers, which are still there.
- A real-world employee has at least two business partner records to work properly. This became the standard in the newest versions of S4 as the unified option had multiple challenges.
- The main SAP MDM add on (MDG) still has a customer workflow side (MDG-C) and a vendor workflow side (MDG-V).
The Business Balancing Act
Though the technical uptake is there, the business uptake is slower.
In all the SAP and D365 renewal projects I have been involved in, there were concerns from parts of the business side about aligning sell-side customer-facing processes and buy-side vendor-facing processes and thus harvesting any business benefits around a unified handling of the two most prominent entities in the business partner / party concept.
The main reasons for the unified approach are:
- You will always find that many real-world entities have a vendor role as well as a customer role to you.
- The basic master data has the same structure (identification, names, addresses and contact data.
- You need the same third-party validation and enrichment capabilities for customer roles and vendor roles.
The main arguments against, as I have heard them, are:
- I don’t care.
- So what?
- Well, yes, but that is a thin business case against all the needed change management.
What are the pros and cons that you have experienced?

 A pearl is a popular gemstone. Natural pearls, meaning they have occurred spontaneously in the wild, are very rare. Instead, most are farmed in fresh water and therefore by regulation used in many countries must be referred to as cultured freshwater pearls.
A pearl is a popular gemstone. Natural pearls, meaning they have occurred spontaneously in the wild, are very rare. Instead, most are farmed in fresh water and therefore by regulation used in many countries must be referred to as cultured freshwater pearls. When selecting an identifier there are different options as national IDs, LEI, DUNS Number and others as explained in the post
When selecting an identifier there are different options as national IDs, LEI, DUNS Number and others as explained in the post 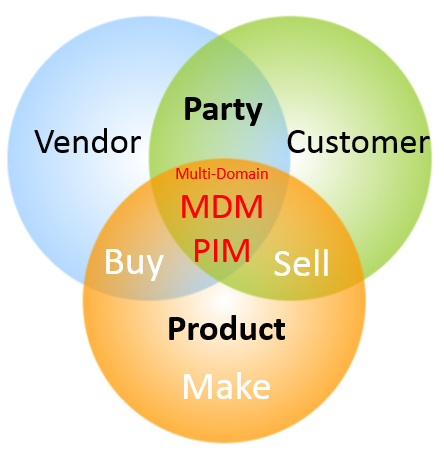
 An important part of implementing Master Data Management (MDM) is to capture the business rules that exists within the implementing organization and build those rules into the solution. In addition, and maybe even more important, is the quest of crafting new business rules that helps making master data being of more value to the implementing organization.
An important part of implementing Master Data Management (MDM) is to capture the business rules that exists within the implementing organization and build those rules into the solution. In addition, and maybe even more important, is the quest of crafting new business rules that helps making master data being of more value to the implementing organization.
 While the innovators and early adopters are fighting with big data quality the late majority are still trying get the heads around how to manage small data. And that is a good thing, because you cannot utilize big data without solving small data quality problems not at least around master data as told in the post
While the innovators and early adopters are fighting with big data quality the late majority are still trying get the heads around how to manage small data. And that is a good thing, because you cannot utilize big data without solving small data quality problems not at least around master data as told in the post  Solving data quality problems is not just about fixing data. It is very much also about fixing the structures around data as explained in a post, featuring the pope, called
Solving data quality problems is not just about fixing data. It is very much also about fixing the structures around data as explained in a post, featuring the pope, called  A common roadblock on the way to solving data quality issues is that things that what are everybody’s problem tends to be no ones problem. Implementing a data governance programme is evolving as the answer to that conundrum. As many things in life data governance is about to think big and start small as told in the post
A common roadblock on the way to solving data quality issues is that things that what are everybody’s problem tends to be no ones problem. Implementing a data governance programme is evolving as the answer to that conundrum. As many things in life data governance is about to think big and start small as told in the post  Data governance revolves a lot around peoples roles and there are also some specific roles within data governance. Data owners have been known for a long time, data stewards have been around some time and now we also see Chief Data Officers emerge as examined in the post
Data governance revolves a lot around peoples roles and there are also some specific roles within data governance. Data owners have been known for a long time, data stewards have been around some time and now we also see Chief Data Officers emerge as examined in the post 
 If we look at customer, or rather party, Master Data Management (MDM) it is much about real world alignment. In party master data management you describe entities as persons and legal entities in the real world and you should have descriptions that reflect the current state (and sometimes historical states) of these entities. Some reflections will be
If we look at customer, or rather party, Master Data Management (MDM) it is much about real world alignment. In party master data management you describe entities as persons and legal entities in the real world and you should have descriptions that reflect the current state (and sometimes historical states) of these entities. Some reflections will be 