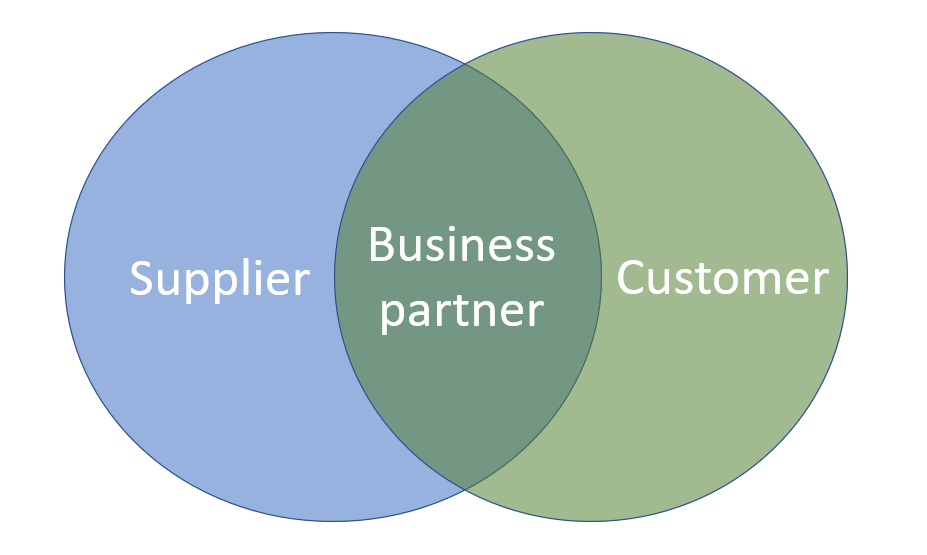
Since the birth of this blog one of the key concepts that has been repeatedly visited is the business partner / party concept in Master Data Management (MDM). This concept is about unifying the handling of data about customers, vendors, contacts, employees and other real-world objects that are all legal entities. One of the first posts from 16 years back was called 360° Business Partner View.
Since then, the uptake for this idea has been greatly helped by all the major ERP vendors over the years, as they have adopted this concept in their newer data models.
This is true for SAP, where the business partner concept was introduced as an option in the old ECC system and now has become the overarching concept is the new S4 system. The concept in S4 is explained by SAP here.
Also, Microsoft has adopted a party concept in their D365 solution. This is explained here.

The Technical Balancing Act
While the data models have been twisted to reflect the business partner / party concept in principle, there are still some halfway solutions in force.
For SAP some examples I have come across are:
- The hierarchy management is for some purposes better suited for the business partner layer and for other purposes better suited for the underlaying customer or vendor layers, which are still there.
- A real-world employee has at least two business partner records to work properly. This became the standard in the newest versions of S4 as the unified option had multiple challenges.
- The main SAP MDM add on (MDG) still has a customer workflow side (MDG-C) and a vendor workflow side (MDG-V).
The Business Balancing Act
Though the technical uptake is there, the business uptake is slower.
In all the SAP and D365 renewal projects I have been involved in, there were concerns from parts of the business side about aligning sell-side customer-facing processes and buy-side vendor-facing processes and thus harvesting any business benefits around a unified handling of the two most prominent entities in the business partner / party concept.
The main reasons for the unified approach are:
- You will always find that many real-world entities have a vendor role as well as a customer role to you.
- The basic master data has the same structure (identification, names, addresses and contact data.
- You need the same third-party validation and enrichment capabilities for customer roles and vendor roles.
The main arguments against, as I have heard them, are:
- I don’t care.
- So what?
- Well, yes, but that is a thin business case against all the needed change management.
What are the pros and cons that you have experienced?