The latest Gartner Hype Cycle for Data and Analytics Governance and Master Data Management includes some of the MDM trends that have been touched here on the blog.
If we look at the post peak side, there are these five terms in motion:
- Single domain MDM represented by the two most common domains being MDM of Product Data and MDM of Customer Data.
- Multidomain MDM.
- Interenterprise MDM, which before was coined Multienterprise MDM by Gartner and as I like to coin Ecosystem Wide MDM.
- Data Hub Strategy which I like to coin Extended MDM.
- Cloud MDM.

The hype cycle from last year was examined in the post MDM Terms in Use in the Gartner Hype Cycle.
Compared to last year this has happened to MDM:
- Multidomain MDM has moved on from the Trough of Disillusionment to climbing up the Slope of Enlightenment. I have been waiting for this to happen for 10 years – both in the hype cycle and in the real-world – since I founded the Multi-Domain MDM Group on LinkedIn back then.
- Interinterprise MDM has swapped place with Cloud MDM, so this term is now ahead of Cloud MDM. It is though hard to imagine Interenterprise MDM without Cloud MDM, and MDM in the cloud will also according Gartner reach the the Plateau of Productivity before ecosystem wide MDM. The promise of this is also in accordance with a poll I made as told in the post Interenterprise MDM Will be Hot.
You can get the full report from the MDM consultancy parsionate here.

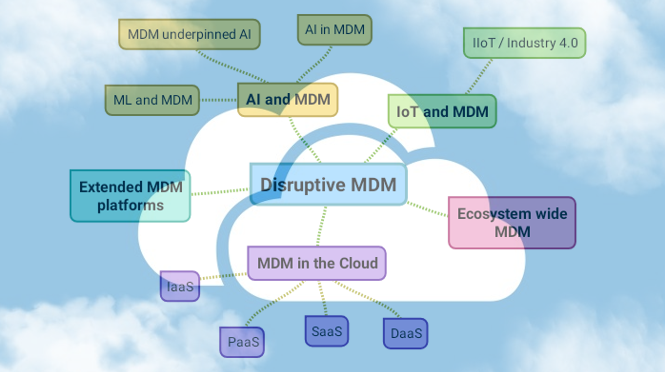




 Some of the topics I find to be the most promising visit points on this journey are cloud deployment of MDM solutions, inclusion of Artificial Intelligence (AI) in MDM and multienterprise MDM.
Some of the topics I find to be the most promising visit points on this journey are cloud deployment of MDM solutions, inclusion of Artificial Intelligence (AI) in MDM and multienterprise MDM.
