The terms “Single Customer View” (SCV) and “360 View of Customer” have been commonly used within the field of Master Data Management (MDM) since things started with the very first Customer Data Integration (CDI) solutions.
The theory is simple: A customer MDM solution creates golden records that uniquely identify any person or business who is a customer of your organization. The solution then builds out a complete description of those persons and businesses which serves as the single source of truth.
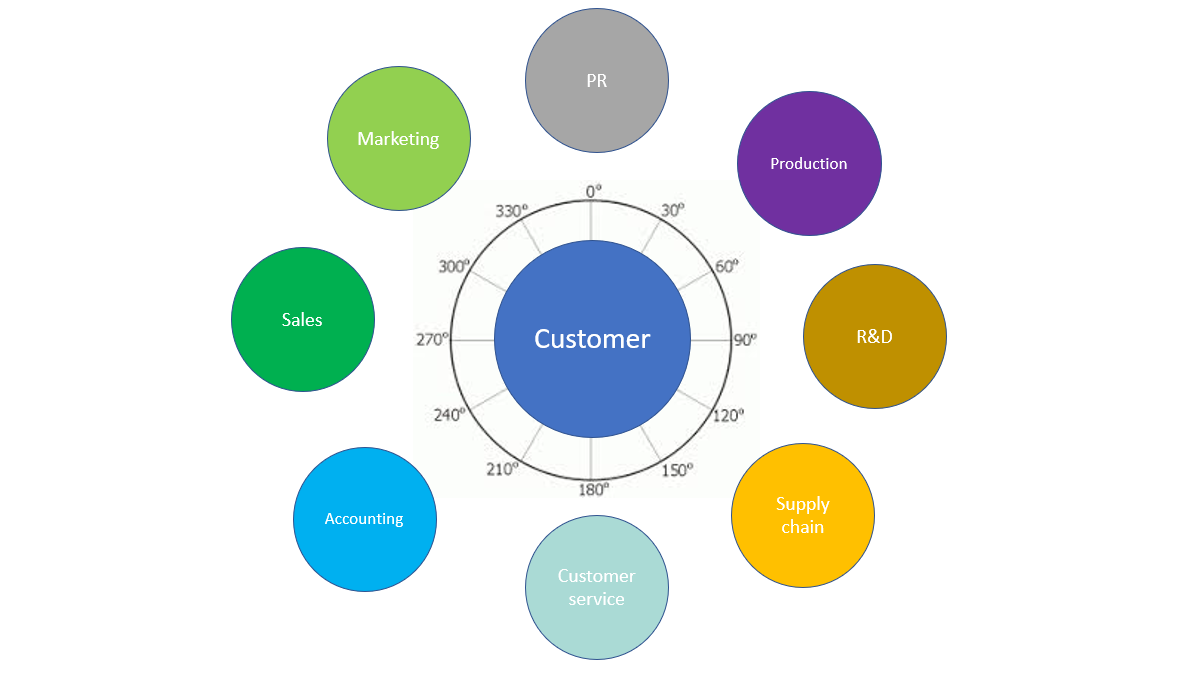
In practice, this is very hard. Compiling a concept for a view that suits all scenarios across all business units is often too daunting; the challenges involved in this effort often kill off the customer MDM implementation before completion. This is sad, because it is also hard to succeed in digital transformation and launch new digital services when you have unconnected customer views scattered across the application landscape within your organization.
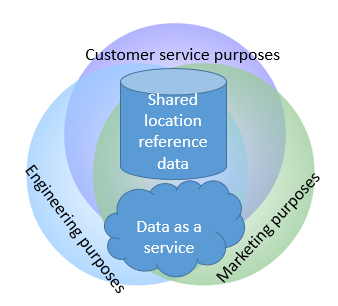
Therefore, building context-aware customer views is a very useful concept when you want to deliver successful customer MDM implementations and digital transformation projects.
Learn more about this in the white paper co-authored by Reltio and yours truly: Taking Customer 360 to The Next Level: Fueling New Digital Business




 Nope, there is no such thing as a single version of the truth.
Nope, there is no such thing as a single version of the truth. “No one dared to admit that he couldn’t see anything, for who would want it to be known that he was either stupid or unfit for his post?”
“No one dared to admit that he couldn’t see anything, for who would want it to be known that he was either stupid or unfit for his post?” Using third party data for customer and supplier master data seems to be a very good idea as exemplified in the post
Using third party data for customer and supplier master data seems to be a very good idea as exemplified in the post 

 While MDM solutions since then have been picking up on the share of the data matching being done around it is still a fairly small proportion of data matching that is performed within MDM solutions. Even if you have a MDM solution with data matching capabilities, you might still consider where data matching should be done. Some considerations I have come across are:
While MDM solutions since then have been picking up on the share of the data matching being done around it is still a fairly small proportion of data matching that is performed within MDM solutions. Even if you have a MDM solution with data matching capabilities, you might still consider where data matching should be done. Some considerations I have come across are: