
I am very pleased to welcome today’s guest blogger. Canada based Maira Bay de Souza of Product Data Lake Technologies shares her view on data integration and the mistakes to avoid doing that:
Throughout my 5 years of working with Data Integration, Data Migration and Data Architecture, I’ve noticed some common (but sometimes serious) mistakes related to Data Management and Software Quality Management. I hope that by reading about them you will be able to avoid them in your future Data Integration projects.
1 Ignoring Data Architecture
Defining the Data Architecture in a Data Integration project is the equivalent of defining the Requirements in a normal (non-data-oriented) software project. A normal software application is (most of the times) defined by its actions and interactions with the user. That’s why, in the first phase of software development (the Requirements Phase), one of the key steps is creating Use-Cases (or User Stories). On the other hand, a Data Integration application is defined by its operations on datasets. Interacting with data structures is at the core of its functionality. Therefore, we need to have a clear picture of what these data structures look like in order to define what operations we will do on them.
It is widely accepted in normal software development that having well-defined requirements is key to success. The common saying “If you don’t know where you’re going, any road will get you there” also applies for Data Integration applications. When ETL developers don’t have a clear definition of the Data Architecture they’re working with, they will inevitably make assumptions. Those assumptions might not always be the same as the ones you, or worse, your customer made.
(see here and here for more examples on the consequences of not finding software bugs early in the process due to by badly defined requirements)
Simple but detailed questions like “can this field be null or not?” need to be answered. If the wrong decision is made, it can have serious consequences. Most senior Java programmers like me are well aware of the infamous “Null Pointer Exception“. If you feed a null value to a variable that doesn’t accept null (but you don’t know that that’s the case because you’ve never seen any architecture specification), you will get that error message. Because it is a vague message, it can be time-consuming to debug and find the root cause (especially for junior programmers): you have to open your ETL in the IDE, go to the code view, find the line of code that is causing the problem (sometimes you might even have to run the ETL yourself), then find where that variable is located in the design view of your IDE, add a fix there, test it to make sure it’s working and then deploy it in production again. That also means that normally, this error causes an ETL application to stop functioning altogether (unless there is some sort of error handling). Depending on your domain that can have serious, life-threatening consequences (for example, healthcare or aviation), or lead to major financial losses (for example, e-commerce).
Knowing the format, boundaries, constraints, relationships and other information about your data is imperative to developing a high quality Data Integration application. Taking the time to define the Data Architecture will prevent a lot of problems down the road.
2 Doing Shallow Data Profiling
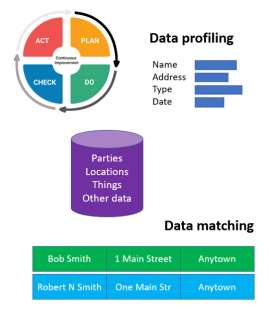
Data profiling is another key element to developing good Data Integration applications.
When doing data profiling, most ETL developers look at the current dataset in front of them, and develop the ETL to clean and process the data in that dataset. But unfortunately that is not enough. It is important to also think about how the dataset might change over time.
For example, let’s say we find a customer in our dataset with the postal code in the city field. We then add an instruction in the ETL for when we find that specific customer’s data, to extract the postal code from the city field and put it in the postal code field. That works well for the current dataset. But what if next time we run the ETL another customer has the same problem? (it could be because the postal code field only accepts numbers and now we are starting to have Canadian customers, who have numbers and letters in the postal code, so the user started putting the postal code in the city field)
Not thinking about future datasets means your ETL will only work for the current dataset. However, we all know that data can change over time (as seen in the example above) – and if it is inputted by the user, it can change unpredictably. If you don’t want to be making updates to your ETL every week or month, you need to make it flexible enough to handle changes in the dataset. You should use data profiling not only to analise current data, but also to deduce how it might change over time.
Doing deep data profiling in the beginning of your project means you will spend less time making updates to the Data Cleaning portion of your ETL in the future.
3 Ignoring Data Governance
This point goes hand-in-hand with my last one.
A good software quality professional will always think about the “what if” situations when designing their tests (as opposed to writing tests just to “make sure it works”). In my 9 years of software testing experience, I can’t tell you how many times I asked a requirements analyst “what if the user does/enters [insert strange combination of actions/inputs here]?” and the answer was almost always “the user will never do that“. But the reality is that users are unpredictable, and there have been several times when the user did what they “would never do” with the applications I’ve tested.
The same applies to data being inputted into an ETL. Thinking that “data will never come this way” is similar to saying “the user will never do that“. It’s better to be prepared for unexpected changes in the dataset instead of leaving it to be fixed later on, when the problem has already spread across several different systems and data stores. For example, it’s better to add validation steps to make sure that a postal code is in the right format, instead of making no validation and later finding provinces in the postal code field. Depending on your data structures, how dirty the data is and how widespread the problem is, the cost to clean it can be prohibitive.
This also relates to my first point: a well-defined Data Architecture is the starting point to implementing Data Governance controls.
When designing a high quality Data Integration application, it’s important to think of what might go wrong, and imagine how data (especially if it’s inputted by a human) might be completely different than you expect. As demonstrated in the example above, designing a robust ETL can save hours of expensive manual data cleaning in the future.
4 Confusing Agile with Code-And-Fix
A classic mistake in startups and small software companies (especially those ran by people without a comprehensive education or background in Software Engineering) is rushing into coding and leaving design and documentation behind. That’s why the US Military and CMU created the CMMI: to measure how (dis)organized a software company is, and help them move from amateur to professional software development. However, the compliance requirements for a high maturity organization are impractical for small teams. So things like XP, Agile, Scrum, Lean, etc have been used to make small software teams more organized without getting slowed down by compliance paperwork.
Those techniques, along with iterative development, proved to be great for startups and innovative projects due to their flexibility. However, they can also be a slippery slope, especially if managers don’t understand the importance of things like design and documentation. When the deadlines are hanging over a team’s head, the tendency is always to jump into coding and leave everything else behind. With time, managers start confusing agile and iterative development with code-and-fix.
Throughout my 16 years of experience in the Software Industry, I have been in teams where Agile development worked very well. But I have also been in teams where it didn’t work well at all – because it was code-and-fix disguised as Agile. Doing things efficiently is not the same as skipping steps.
Unfortunately, in my experience this is no different in ETL development. Because it is such a new and unpopular discipline (as opposed to, for example, web development), there aren’t a lot of software engineering tools and techniques around it. ETL design patterns are still in their infancy, still being researched and perfected in the academic world. So the slippery slope from Agile to code-and-fix is even more tempting.
What is the solution then? My recommendation is to use the proven, existing software engineering tools and techniques (like design patterns, UML, etc) and adapt them to ETL development. The key here is to do something. The fact that there is a gap in the industry’s body of knowledge is no excuse for skipping requirements, design, or testing, and jumping into “code-and-fix disguised as Agile“. Experiment, adapt and find out which tools, methodologies and techniques (normally used in other types of software development) will work for your ETL projects and teams.
5 Not Paying Down Your Technical Debt
The idea of postponing parts of your to-do list until later because you only have time to complete a portion of them now is not new. But unfortunately, with the popularization of agile methodologies and incremental development, Technical Debt has become an easy way out of running behind schedule or budget (and masking the root cause of the problem which was an unrealistic estimate).
As you might have guessed, I am not the world’s biggest fan of Technical Debt. But I understand that there are time and money constraints in every project. And even the best estimates can sometimes be very far from reality – especially when you’re dealing with a technology that is new for your team. So I am ok with Technical Debt, when it makes sense.
However, some managers seem to think that technical debt is a magic box where we can place all our complex bugs, and somehow they will get less complex with time. Unfortunately, in my experience, what happens is the exact opposite: the longer you owe technical debt (and the more you keep adding to it), the more complex and patchy the application becomes. If you keep developing on top of – or even around – an application that has a complex flaw, it is very likely that you will only increase the complexity of the problem. Even worse, if you keep adding other complex flaws on top of – or again, even around – it, the application becomes exponentially complex. Your developers will want to run away each time they need to maintain it. Pretty soon you end up with a piece of software that looks more like a Frankenstein monster than a clean, cohesive, elegant solution to a real-world problem. It is then only a matter of time (usually very short time) before it stops working altogether and you have no choice but to redesign it from scratch.
This (unfortunately) frequent scenario in software development is already a nightmare in regular (non-data-oriented) software applications. But when you are dealing with Data Integration applications, the impact of dirty data or ever-changing data (especially if it’s inputted by a human), combined with the other 4 Data Management mistakes I mentioned above, can quickly escalate this scenario into a catastrophe of epic proportions.
So how do you prevent that from happening? First of all, you need to have a plan for when you will pay your technical debt (especially if it is a complex bug). The more complex the required change or bug is, the sooner it should be dealt with. If it impacts a lot of other modules in your application or ecosystem, it is also important to pay it off sooner rather than later. Secondly, you need to understand why you had to go into technical debt, so that you can prevent it from happening again. For example, if you had to postpone features because you didn’t get to them, then you need to look at why that happened. Did you under-estimate another feature’s complexity? Did you fail to account for unknown unknowns in your estimate? Did sales or your superior impose an unrealistic estimate on your team? The key is to stop the problem on its tracks and make sure it doesn’t happen again. Technical Debt can be helpful at times, but you need to manage it wisely.
I hope you learned something from this list, and will try to avoid these 5 Data Management and Software Quality Management mistakes on your next projects. If you need help with Data Management or Software Quality Management, please contact me for a free 15-min consultation.
Maira holds a Bsc in Computer Science, 2 software quality certifications and over 16 years of experience in the Software Industry. Her open-mindedness and adaptability have allowed her to thrive in a multidisciplinary career that includes Software Development, Quality Assurance and Project Management. She has taken senior and consultant roles at Fortune 20 companies (IBM and HP), as well as medium and small businesses. She has spent the last 5 years helping clients manage and develop software for Data Migration, Data Integration, Data Quality and Data Consistency. She is a Product Data Lake Ambassador & Technology Integrator through her startup Product Data Lake Technologies.
 PS: The next feature on the site is planned to be The Case Study List. Stay tuned.
PS: The next feature on the site is planned to be The Case Study List. Stay tuned.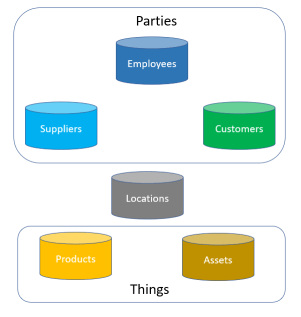



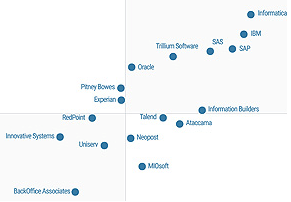 The 2016 Magic Quadrant for Data Quality Tools by Gartner is out. One way to have a free read is
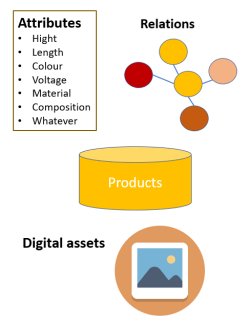
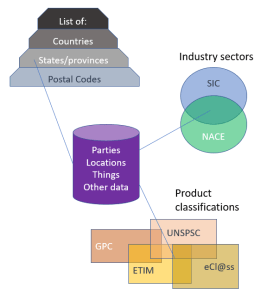
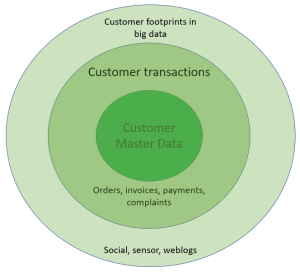
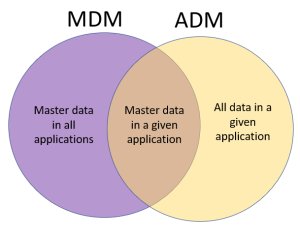
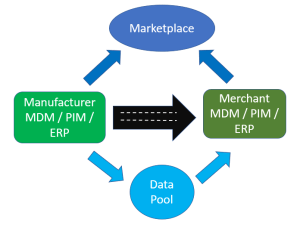
The 2016 Magic Quadrant for Data Quality Tools by Gartner is out. One way to have a free read is  With product master data we also have Product Information Management (PIM) solutions. From what I have seen PIM solutions has one key capability that is essentially different from a common database solution and how many MDM solutions, that are built with party master data in mind, has. That is a flexible and super user angled way of building hierarchies and assigning attributes to entities – in this case particularly products. If you offer customer self-service, like in eCommerce, with products that have varying attributes you need PIM functionality. If you want to do this smart, you need a collaboration environment for supplier self-service as well as pondered in the post
With product master data we also have Product Information Management (PIM) solutions. From what I have seen PIM solutions has one key capability that is essentially different from a common database solution and how many MDM solutions, that are built with party master data in mind, has. That is a flexible and super user angled way of building hierarchies and assigning attributes to entities – in this case particularly products. If you offer customer self-service, like in eCommerce, with products that have varying attributes you need PIM functionality. If you want to do this smart, you need a collaboration environment for supplier self-service as well as pondered in the post 





{kind=link}