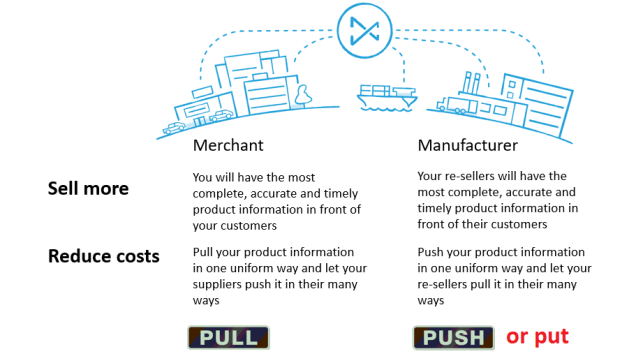
One of the bottlenecks in Product Information Management (PIM) is getting product data ready for presentation to the buying audience as fast as possible.
Product data travels a long way from the origin at the manufacturing company, perhaps through distributors and wholesalers to the merchant or marketplace. In that journey the data undergo transformation (and translation) from the state it has at the producing organization to the state chosen by the selling organization.
However, time to market is crucial. This applies to when a new product range is chosen by the merchant or when there are changes and improvements at the manufacturer.
At Product Data Lake we enable a much faster pace in these quests than when doing this by using emails, spreadsheets and passive portals.
Take two minutes to test if your company is exchanging product data at the speed of a cheetah or a garden snail.

 Building materials is a very diverse product group. As a wholesaler or dealer, you will have to manage many different attributes and digital assets depending on which product classification we are talking about.
Building materials is a very diverse product group. As a wholesaler or dealer, you will have to manage many different attributes and digital assets depending on which product classification we are talking about.


 This reminds me of when we talk about using robots to substitute human labor. Then we often think about a machine that looks like a human. But effective industrial robots do not look like humans. They a designed to do a specific process much more effective than a human and will therefore not look like a human. The same is true in digitalization. When we redesign business processes to be much more effective they should not include spreadsheets.
This reminds me of when we talk about using robots to substitute human labor. Then we often think about a machine that looks like a human. But effective industrial robots do not look like humans. They a designed to do a specific process much more effective than a human and will therefore not look like a human. The same is true in digitalization. When we redesign business processes to be much more effective they should not include spreadsheets.