The term family is used in different contexts within Master Data Management (MDM), Data Quality Management (DQM) and Product Information Management (PIM) when working with hierarchy management and entity resolution.
Here are three frequent examples:
Consumer / citizen family
 When handling party master data about consumers / citizens we can deal with the basic definition of a family, being a group consisting of two parents and their children living together as a unit.
When handling party master data about consumers / citizens we can deal with the basic definition of a family, being a group consisting of two parents and their children living together as a unit.
This is used when the business scenario does not only target each individual person but also a household with a shared economy. When identifying a household, a common parameter is that the persons live on the same postal address (at the same time) while observing constellations as:
- Nuclear families consisting of a female and a male adult (and their children)
- Rainbow families where the gender is not an issue
- Extended families consisting of more than two generations
- Persons who happen to live on the same postal address
There are multicultural aspects of these constellations including the different family name constructions around the world and the various frequency and acceptance of rainbow families as well of frequency of extended families.
Company family tree
When handling party master data about companies / organizations a valuable information is how the companies / organizations are related most commonly pictured as a company family tree with mothers and sisters. This can in theory be in infinite levels. The basic levels are:
- A global ultimate mother being the company that ultimately owns (fully or partly) a range of companies in several countries.
- A national ultimate mother being the company that owns (fully or partly) a range of companies in a given country.
- A legal entity being the basic registered company within a country having some form of a business entity identifier.
- A branch owned by a legal entity and operating from a given postal / visiting address.
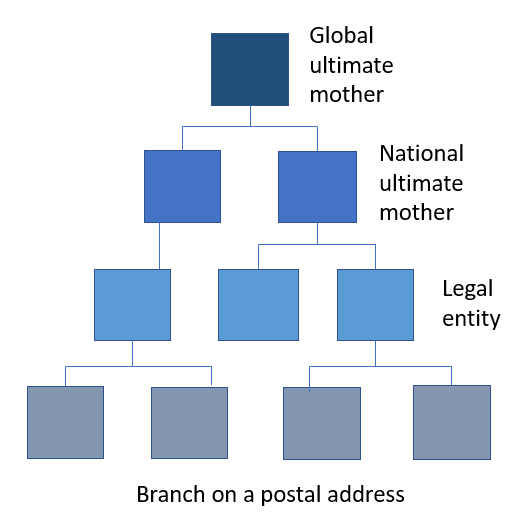 You can build your own company tree describing your customers, suppliers and other business partners. Alternatively or supplementary, you can rely on third party business directories. It is here worth noticing that a national source will only go to the ultimate national mother level while a global source can include the global ultimate mother and thus form larger families.
You can build your own company tree describing your customers, suppliers and other business partners. Alternatively or supplementary, you can rely on third party business directories. It is here worth noticing that a national source will only go to the ultimate national mother level while a global source can include the global ultimate mother and thus form larger families.
Having a company family view in your master data repository is a valuable information asset within credit risk, supply risk, discount opportunities, cross-selling and more.
Product family
The term “product family” is often used to define a level in a homegrown product classification / product grouping scheme. It is used to define a level that can have levels above and levels below with other terms as “product line”, “product category”, “product class”, “product group”, “product type” and more.
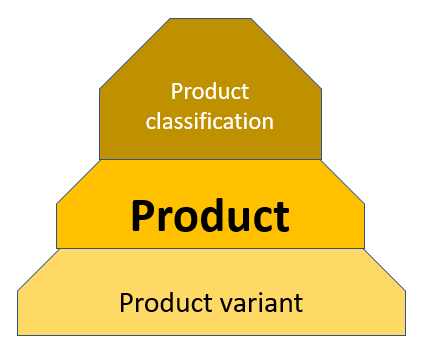 Sometimes it is also used as a term to define a product with a family of variants below, where variants are the same product produced and kept in stock in different colours, sizes and more.
Sometimes it is also used as a term to define a product with a family of variants below, where variants are the same product produced and kept in stock in different colours, sizes and more.
Read more about Stock Keeping Units (SKUs), product variants, product identification and product classification in the post Five Product Information Management Core Aspects.

 Business directories:
Business directories:





