One problem with having English as the lingua franca on this planet is that English have a lot of different words meaning (almost) the same. One example is product, material, article, and item. This entity is the core entity within the master data domain we usually call the product domain.
I have experienced numerous occasions where these words are used to describe different perspectives across lifecycles or granularity in different ways within the same organization operating in manufacturing, distribution, retail, construction or comparable industry.

Product
The word product is part of the product domain in Master Data Management (MDM). It is also part of the adjacent discipline called Product Information Management (PIM). Also, it is part of the upcoming Digital Product Passport (DPP).
Furthermore, the word product is part of the term Universal Product Code (UPC) which is the North American version of the Global Trade Identification Number (GTIN).
We also have the word product as part of the term finished product.
If product is not the overarching term for material, article, and item it is often seen as either:
- The sellable thing that comes out of a manufacturing process.
- A higher level in a product hierarchy where there are varying articles/items on a lower level.
Material
In SAP, the predominant ERP application on this planet, the core product entity is called material.
We also have the word material as part of the term raw material.
Material is often seen as a thing that goes into a manufacturing or construction process.
Article
The word article is part of the term International Article Number previously known as European Article Number (EAN) which is the European version of the Global Trade Identification Number (GTIN).
An article is often seen as the level in a product hierarchy where you can assign a GTIN, meaning that the articles with the same GTIN have the same dimensions, color, other specifications, and packing.
This is equivalent to the term Stock Keeping Unit (SKU).
Item
Item is often used as an alternative or neutral term for product, material and/or article. Item is widely used as a column header for the sold products/materials/articles on an sales order and invoice or the requested products/materials/articles on a purchase order.
Proper use
As with so many other similar terms there is no generic proper use that your organization can stick to. There may be a trend or standard in your industry you can adhere to. Anyway, your data governance framework should be able to state the proper use within your organization as part of a business glossary.
Have you formed a business glossary or similar construct that defines how the words product/material/article/item/whatever (in your official language) should be used?


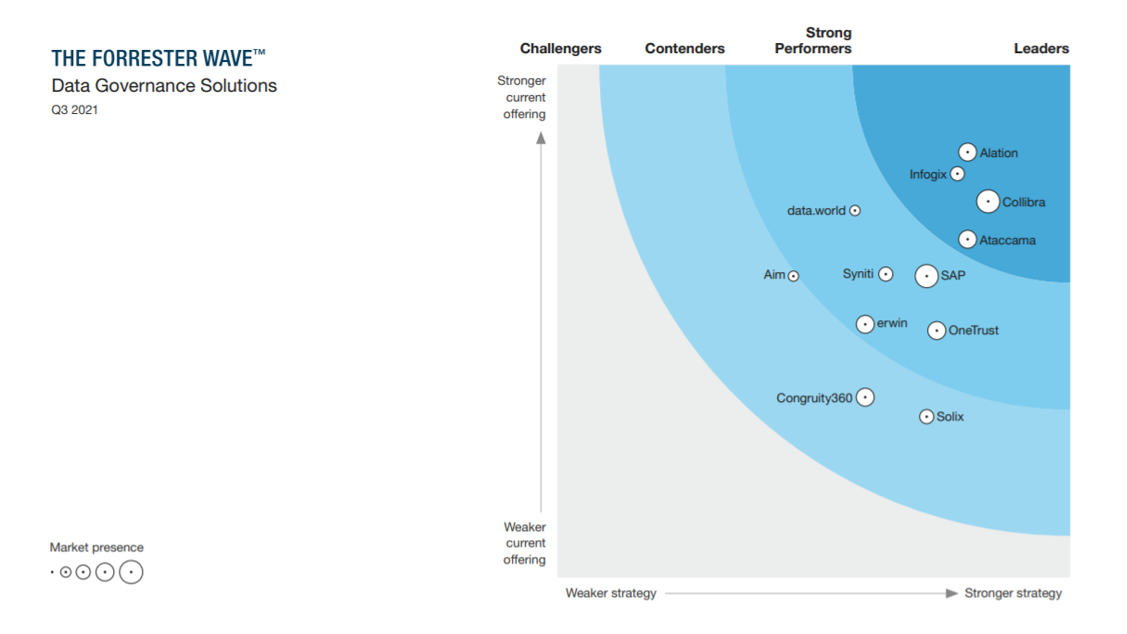




 PS: The next feature on the site is planned to be The Case Study List. Stay tuned.
PS: The next feature on the site is planned to be The Case Study List. Stay tuned.