The title of this post is also the title of my presentation at the Master Data Management Summit Europe 2019. This conference is co-located with the Data Governance Conference Europe 2019.
The session will go through these topics:
- Why business ecosystem wide MDM will be on the future agenda as elaborated in a post on this blog. The post is called Ecosystem Wide MDM.
- What exactly is multienterprise MDM as examined in a post on The Disruptive Master Data Management Solutions List.
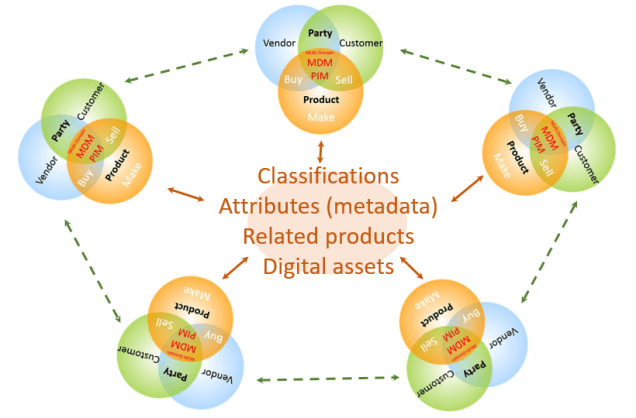
- How does it apply to party master data and what about data privacy and data protection?
- How can multienterprise MDM be used within product MDM and what is the link to IoT (Internet of Things).
- Learn from a concrete use case encompassing product information and AI (Artificial Intelligence) as mentioned in the post It is time to apply AI to MDM and PIM.
You can have a look at the entire agenda at the MDMDG Summit Europe 2019 here.
 The Sponsors
The Sponsors I second that, having been working with the
I second that, having been working with the 
 I am looking forward to visiting London in a fortnight and have already secured tickets for the new musical called
I am looking forward to visiting London in a fortnight and have already secured tickets for the new musical called  Semarchy, who has always been kind of kinky with their evolutionary MDM approach as told in the post
Semarchy, who has always been kind of kinky with their evolutionary MDM approach as told in the post  Ataccama has a kinky logo. Also on a recent engagement, we have been working with the data quality analyzer tool from Ataccama. So will be good to learn about all the other stuff as for example the
Ataccama has a kinky logo. Also on a recent engagement, we have been working with the data quality analyzer tool from Ataccama. So will be good to learn about all the other stuff as for example the  Stibo Systems, where I worked some years ago, has just released their new
Stibo Systems, where I worked some years ago, has just released their new