The latest Information Difference Data Quality Landscape is out. This is a generic ranking of major data quality tools on the market.

You can see the previous data quality landscape in the post Congrats to Datactics for Having the Happiest DQM Customers.
There are not any significant changes in the relative positioning of the vendors. Only thing is that Syncsort has been renamed to Precisely.
As stated in the report, much of the data quality industry is focused on name and address validation. However, there are many opportunities for data quality vendors to spread their wings and better tackle problems in other data domains, such as product, asset and inventory data.
One explanation of why this is not happening is probably the interwoven structure of the joint Master Data Management (MDM), Product Information Management (PIM) and Data Quality Management (DQM) markets and disciplines. For example, a predominant data quality issue as completeness of product information is addressed in PIM solutions and even better in Product Data Syndication (PDS) solutions.
Here, there are some opportunities for pure play vendors within each speciality to work together as well as for the larger vendors for offering both a true integrated overall solution as well as contextual solutions for each issue with a reasonable cost/benefit ratio.









 The selection model is based on the context, scope and requirements for your solution.
The selection model is based on the context, scope and requirements for your solution. The solution capabilities considered in the selection process are those of who are:
The solution capabilities considered in the selection process are those of who are: These two sets of information are compared in a continuously supervised learning algorithm – also known in marketing as machine learning and artificial intelligence (AI).
These two sets of information are compared in a continuously supervised learning algorithm – also known in marketing as machine learning and artificial intelligence (AI).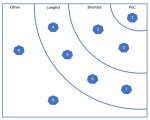 The outcome is:
The outcome is: PS: The next feature on the site is planned to be The Case Study List. Stay tuned.
PS: The next feature on the site is planned to be The Case Study List. Stay tuned.