The data governance discipline, the Master Data Management (MDM) discipline and the data quality discipline are closely related and happens to be my fields of work as told in the post Data Governance, Data Quality and MDM.
Every IT enabled discipline has an element of understanding people, orchestrating business processes and using technology. The mix may vary between disciplines. This is also true for the three above-mentioned disciplines.
But how important is people, process and technology within these three disciplines? Are the disciplines very different in that perspective? I think so.
When assigning a value from 1 (less important) to 5 (very important) for Data Governance (DG), Master Data Management (MDM) and Data Quality (DQ) I came to this result:
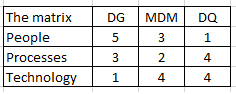
A few words about the reasoning for the highs and lows:
Data governance is in my experience a lot about understanding people and less about using technology as told in the post Data Governance Tools: The New Snake Oil?
I often see arguments about that data quality is all about people too. But:
- I think you are really talking about data governance when putting the people argument forward in the quest for achieving adequate data quality.
- I see little room for having the personal opinion of different people dictating what adequate data quality is. This should really be as objective as possible.
Now I am ready for your relentless criticism.
![]()


 The post refers to a report by Sunil Soares. In this report data governance tools are seen as tools related to six areas within enterprise data management: Data discovery, data quality, business glossary, metadata, information policy management and reference data management.
The post refers to a report by Sunil Soares. In this report data governance tools are seen as tools related to six areas within enterprise data management: Data discovery, data quality, business glossary, metadata, information policy management and reference data management.