My answer to the question in the title of this blog post is NO. In my eyes big data is not just data warehouse 3.0. It is also data quality 3.0.
The concept of the data lake is growing in popularity in the big data world and so are the counts of warnings about your data lake becoming a data swamp, a data marsh or a data cesspool. Doing analytic work on a nice data lake sounds great. Doing it in a huge swamp, a large marsh or a giant cesspool does not sound so nice.
 In nature a lake stays fresh by having good upstream supply of water and a downstream system as well. In kind of the same way your data lake should not be a closed system or a dump within your organization.
In nature a lake stays fresh by having good upstream supply of water and a downstream system as well. In kind of the same way your data lake should not be a closed system or a dump within your organization.
Sharing data with the outside must be a part of your big data approach. This goes for including traditional flavours of big data as social data and sensor data as well what we may call big reference data being pools of global data and bilateral data as explained on this blog on the page called Data Quality 3.0.
The BrightTalk community on Big Data and Data Management has a formidable collection of webinars and videos on big data and data management topics. I am looking forward to contribute there on the 25th June 2015 with a webinar about Big Reference Data.
![]()
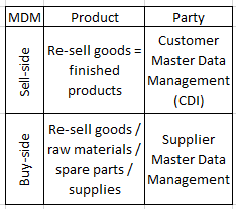 You may argue that PIM (Product Information Management) is not the same as Product MDM. This question was examined in the post
You may argue that PIM (Product Information Management) is not the same as Product MDM. This question was examined in the post 
 While the innovators and early adopters are fighting with big data quality the late majority are still trying get the heads around how to manage small data. And that is a good thing, because you cannot utilize big data without solving small data quality problems not at least around master data as told in the post
While the innovators and early adopters are fighting with big data quality the late majority are still trying get the heads around how to manage small data. And that is a good thing, because you cannot utilize big data without solving small data quality problems not at least around master data as told in the post  Solving data quality problems is not just about fixing data. It is very much also about fixing the structures around data as explained in a post, featuring the pope, called
Solving data quality problems is not just about fixing data. It is very much also about fixing the structures around data as explained in a post, featuring the pope, called  A common roadblock on the way to solving data quality issues is that things that what are everybody’s problem tends to be no ones problem. Implementing a data governance programme is evolving as the answer to that conundrum. As many things in life data governance is about to think big and start small as told in the post
A common roadblock on the way to solving data quality issues is that things that what are everybody’s problem tends to be no ones problem. Implementing a data governance programme is evolving as the answer to that conundrum. As many things in life data governance is about to think big and start small as told in the post  Data governance revolves a lot around peoples roles and there are also some specific roles within data governance. Data owners have been known for a long time, data stewards have been around some time and now we also see Chief Data Officers emerge as examined in the post
Data governance revolves a lot around peoples roles and there are also some specific roles within data governance. Data owners have been known for a long time, data stewards have been around some time and now we also see Chief Data Officers emerge as examined in the post