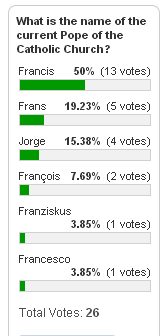
 There has been a quiz running on this blog with the question: What is the name of the current Pope of the Catholic Church?. Find the current standing of answers in the figure to the right.
There has been a quiz running on this blog with the question: What is the name of the current Pope of the Catholic Church?. Find the current standing of answers in the figure to the right.
It’s good to see a lot of different answers and indeed, a problem with the quiz is that all answers may be correct. While Francis is the name as pope in English chosen by Jorge Mario Bergoglio, the pope has other names in other languages as Frans in Danish and Norwegian, François in French, Franziskus in German and Francesco in Italian.
The quiz is actually bad as it has not included other good answers as Franciscus, the latin name, Francisco, the Spanish name, and Franciszek, the Polish name. The question in the quiz is too simple. What is meant by “the name” should be clarified: Is it the birth name, the chosen name as Pope in a given language or what?
Such problems are in fact very common related to what we often see as bad data quality, as it reflects two frequent issues which aren’t about the raw data:
- Data models are too simple. In this case we could be able to reflect different types of names: Birth name and what (sorry, believers) resembles a screen name. And names in various languages.
- Metadata is too weak. In this case it could be more precise what name we are collecting, if it is only one of the name types we need, for example chosen name in English. More about metadata on Wikipedia.
What other issues have you encountered seen as bad data quality, but which isn’t bad raw data?
![]()

Henrik,
Another problem of this kind exists if names have to be transcribed from a different alphabet, e.g. from the Russian (Cyrillic) to the Latin alphabet. As an example, a well-known former Soviet leader may be found (and spelled) as Gorbachyov (transcription according to Wikipedia), Gorbachev (used in English) or Gorbatschow (used in German). As with the pope, there may not be serious problems of identifying famous persons.
However, in the case of the suspected Boston bomber Tamerlan Tsarnaev (the “agreed” spelling in English), depending of the user’s language environment, we also find his family name spelled as Tsarnajew, Tsarnajev, Tsarnaje, Zarnajev which may (not confirmed, but certainly could) have caused a problem of identification during past investigations of this person and consequently may have affected the risk evaluation.
Back to daily business: International organizations definitely need to consider the effect of non-unique transcription in their identification / name matching procedures when having clients from geographic areas that use different alphabets.
Great post and comment. In the US (and many other areas of the world), we also see this problem with nicknames vs legal names. Bob vs Robert or Kat vs Katherine. Matching algorithms must account not only for alternate spellings in various regions of the world, but also any nickname variations.
You also bring up a good point regarding the phrasing of the question. We must be careful to phrase survey questions and form field labels carefully so we have a greater chance of capturing the intended data.
Great post Henrik.
So is this a case of poor Information Quality or is it simply another dimension of Data Quality e.g. Presentation Quality or Metadata Quality that is lacking?
Data becomes information when we relate an item of data to other items of data in context. In this case, if we wanted additional names we would relate our raw data to a mapping of related names, thus inferring information.
Ties in nicely to the other discussion on here recently where I talked about Welsh names. I may call a friend David, his Welsh parents may call him Dafydd but his grandparents may call him Dewi. All names are true facts but if you wanted to dedup his record you would need to have all 3 names mapped to each other to align the context.
Interesting question, application design and model design have to be two of the biggest failure points for DQ, it’s why we get so much overloading of data, stuffing multiple values in one attribute.
– Dylan Jones
http://dataqualitypro.com
Thanks a lot Axel, Tonia and Dylan for adding in.
Interesting post Henrik and very interesting follow up comment from Axel.
Now the question is although many DQ solutions provide transliteration, do global organization really spend resources to this need. If I may play the devil’s advocate is the % of data with them so significant that they spend such significant amount of resources. I mean how may global corporation (and what would be the volume) really have customers spread across say Russia, Greece and America upon whom they would need to apply such dedup rules.
Although, having said that, and considering the stakes invoked I feel there is strong case for federal agencies and state agencies across the major geographies to implement such solutions.
-Vishu