The Product Data Lake is a cloud service for sharing product data in the eco-systems of manufacturers, distributors, retailers and end users of product information.
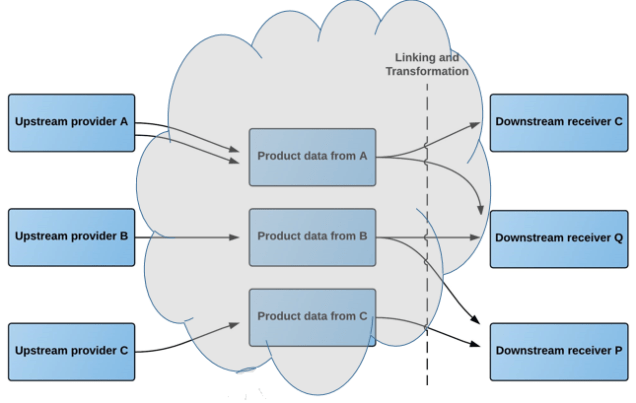 As an upstream provider of products data, being a manufacturer or upstream distributor, you have these requirements:
As an upstream provider of products data, being a manufacturer or upstream distributor, you have these requirements:
- When you introduces new products to the market, you want to make the related product data and digital assets available to your downstream partners in a uniform way
- When you win a new downstream partner you want the means to immediately and professionally provide product data and digital assets for the agreed range
- When you add new products to an existing agreement with a downstream partner, you want to be able to provide product data and digital assets instantly and effortless
- When you update your product data and related digital assets, you want a fast and seamless way of pushing it to your downstream partners
- When you introduce a new product data attribute or digital asset type, you want a fast and seamless way of pushing it to your downstream partners.
The Product Data Lake facilitates these requirements by letting you push your product data into the lake in your in-house structure that may or may not be fully or partly compliant to an international standard.
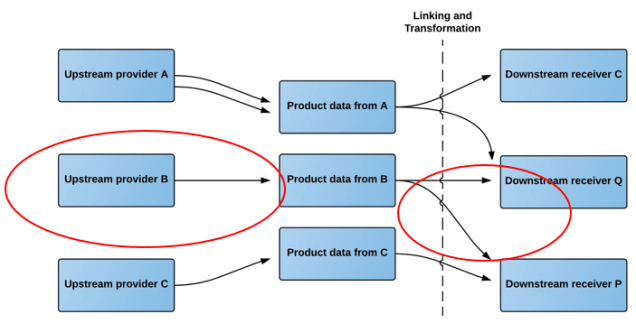
As an upstream provider, you may want to push product data and digital assets from several different internal sources.
The product data lake tackles this requirement by letting you operate several upload profiles.
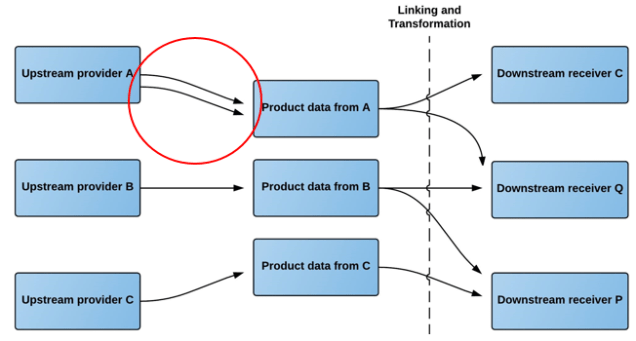
As a downstream receiver of product data, being a downstream distributor, retailer or end user, you have these requirements:
- When you engage with a new upstream partner you want the means to fast and seamless link and transform product data and digital assets for the agreed range from the upstream partner
- When you add new products to an existing agreement with an upstream partner, you want to be able to link and transform product data and digital assets in a fast and seamless way
- When your upstream partners updates their product data and related digital assets, you want to be able to receive the updated product data and digital assets instantly and effortless
- When you introduce a new product data attribute or digital asset type, you want a fast and seamless way of pulling it from your upstream partners
- If you have a backlog of product data and digital asset collection with your upstream partners, you want a fast and cost effective approach to backfill the gap.
The Product Data Lake facilitates these requirements by letting you pull your product data from the lake in your in-house structure that may or may not be fully or partly compliant to an international standard.
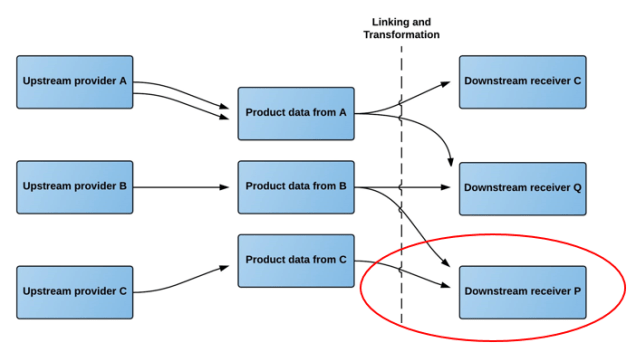
In the Product Data Lake, you can take the role of being an upstream provider and a downstream receiver at the same time by being a midstream subscriber to the Product Data Lake. Thus, Product Data Lake covers the whole supply chain from manufacturing to retail and even the requirements of B2B (Business-to-Business) end users.
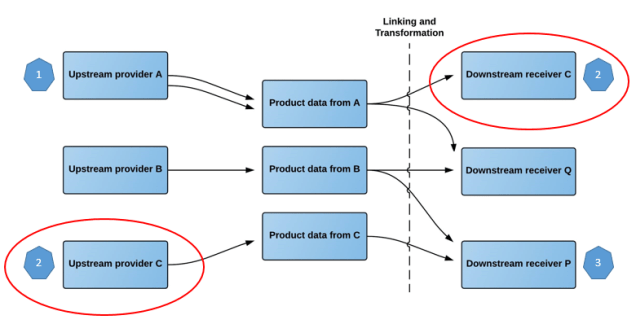
The Product Data Lake uses the data lake concept for big data by letting the transformation and linking of data between many structures be done when data are to be consumed for the first time. The goal is that the workload in this system has the resemblance of an iceberg where 10% of the ice is over water and 90 % is under water. In the Product Data Lake manually setting up the links and transformation rules should be 10 % of the duty and the rest being 90 % of the duty will be automated in the exchange zones between trading partners.



 Data Quality 3.0 is a term I have used over the years here on the blog to describe how I see data quality, along with other disciplines within data management, changing. This change is about going from focusing on internal data stores and cleansing within them to focusing on external sharing of data and using your business ecosystem and third party data to drastically speed up data quality improvement.
Data Quality 3.0 is a term I have used over the years here on the blog to describe how I see data quality, along with other disciplines within data management, changing. This change is about going from focusing on internal data stores and cleansing within them to focusing on external sharing of data and using your business ecosystem and third party data to drastically speed up data quality improvement. In my eyes we need solutions build on the data lake concept if we want business agility – and we do want that. But I also believe that we need to put data in data lakes in context.
In my eyes we need solutions build on the data lake concept if we want business agility – and we do want that. But I also believe that we need to put data in data lakes in context. All these solutions constitutes one of the leading Multi-Domain MDM offerings on the market – if not the leading. We will be wiser on that question when Gartner (the analyst firm) makes their first Multi-Domain MDM Magic Quadrant later this year as reported in the post
All these solutions constitutes one of the leading Multi-Domain MDM offerings on the market – if not the leading. We will be wiser on that question when Gartner (the analyst firm) makes their first Multi-Domain MDM Magic Quadrant later this year as reported in the post 


 But, have any new trends showed up in the past years?
But, have any new trends showed up in the past years?

