One of my pet peeves in data quality for CRM and ERP systems is the often used way at looking at entities, not at least party entities, in a flat data model as told in the post A Place in Time.
Party master data, and related location master data, will eventually be modeled in very complex models and surely we see more and more examples of that. For example I remember that I long time ago worked with the ERP system that later became Microsoft Dynamics AX. Then I had issues with the simplistic and not role aware data model. While I’m currently working in a project using the AX 2012 Address Book it’s good to see that things have certainly developed.
This blog has quite a few posts on hierarchy management in Master Data Management (MDM) and even Hierarchical Data Matching. But I have to admit that even complex relational data models and hierarchical approaches in fact don’t align completely with the real world.
In a comment to the post Five Flavors of Big Data Mike Ferguson asked about graph data quality. In my eyes using graph databases in master data management will indeed bring us closer to the real world and thereby deliver a better data quality for master data.
I remember at this year’s MDM Summit Europe that Aaron Zornes suggested that a graph database will be the best choice for reflecting the most basic reference dataset being The Country List. Oh yes, and in master data too you should think then, though I doubt that the relational database and hierarchy management will be out of fashion for a while.
So it could be good to know if you have seen or worked with graph databases in master data management beyond representing a static analysis result as a graph database.
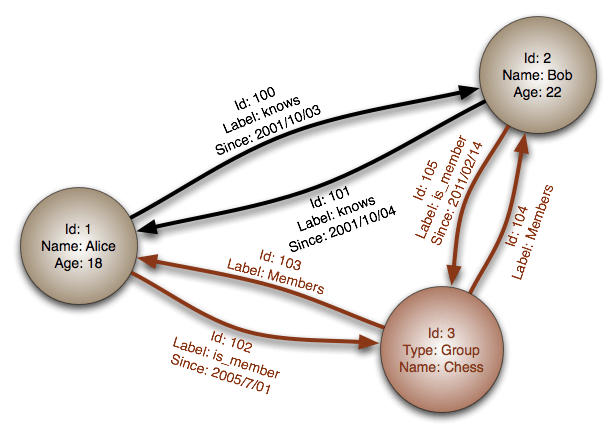
![]()

Henrik, I could not agree more…IMHO, Graph DBMSs and MDM are a good match. I already talk about this in my MDM class. However, I think that given that MDM is already deployed on relational, that RDBMSs that support Graph data stores inside the RDBMS are very likely to become popular platforms for MDM. The key question is if a RDBMS vendor supports Graph data then is there also an inference engine included as well? IMHO, RDBMSs that support both Graph data AND an inference engine are likely to do well in supporting MDM.
Great blog!
While MS Dynamics CRM is obviously based on a relational SQL database, CRM 2011 introduced an entity called ‘connections’ which can link any record to any other record, with a ‘Connection To Role’ and a corresponding ‘Connection From Role’ e.g. Father and Son or Supplier and Consumer. Because it is an entity in of itself you can record other information on it too (e.g. start date, end date, project-specific custom data). Of course the mechanics underneath are not a graph dB but the functionality very closely resembles it (I think) and I make very heavy use of it in most of my projects. The ability to connect any record to any other and include information on the nature of the connection, without the need for enhancement to the data model (creating entity relationships etc.) is a very powerful tool and greatly enriches the data. It does potentially make data extraction/analysis more complicated but I prefer ‘complicated’ to simply ‘not possible’ =D
Hi Henrik
I am not quite in alignment with your assertions here, especially when you state that relational databases do not quite align with the real world. This is just not so.
It is true that if you build relational database without first building a logical data model aligned with the real world, then that database will not align with the real world. But that is not a shortcoming with relational databases. It shows a lack of knowledge and skills on the part of data modelers and database designers and builders.
Getting such practitioners to learn yet another skill that they practice with an equal lack of knowledge and skill will not move the quality of Master Data Management (MDM) further one jot.
In the same way, the current shortcomings in MDM globally have nothing to do with reaching the limitations of relational databases. All of these flaws can be traced back to a) a lack of skills and knowledge of those responsible for modeling corporate master data structures and b) the purchase and implementation of far too many off-the-shelf software packages that fragment master data entities, for example the fragmentation of Party into Customer, Supplier, Agent, Employee, etc. across numerous silo systems.
Graph databases also look worryingly like object oriented databases that 20 years ago were going to solve all of our data problems. What happened I wonder?
They are being promoted as mapping “arbitrary object relations with no intrinsic importance”. I would suggest that any enterprise that is basing the quality of its MDM on such relations might be in a lot of trouble.
Successful MDM does not need new technology. It needs to get the thinking, competencies, skills and practices of its practitioners up to where they need to be. How many MDM practitioners can draw or read a Logical Data Model? If electricians could not read wiring diagrams we would be appalled and not at all surprised if fuses blew and short circuits occurred all over the place.
Well that’s what is happening in MDM. Too few people can draw or read the data wiring diagrams required for MDM and, as a result, data fuses are being blown all over the place.
Regards
John
Thanks a lot Mike, Arthur and John for adding in.
Seems we have a situation of inference versus logic as in a/the logical data model here 🙂
Personally I’m currently in all camps at the same time, by:
• Utilizing better (logical) relational data models as John suggest
• Using more generic features as Arthur suggest
• Exploring the use of graph data stores as Mike suggest
There is another, different, but related question to consider. Do applications built around graph database technology require MDM? If you think duplicates are probematic now, try forging a graph database with duplicte nodes! Not a pretty picture. In order to avoid a tangled mess, creating connections urgently requires uniquely and singularly identifying a person, organization and group represented by a node. Simply think of LinkedIn where everyone has multiple duplicate records. Can you imagine what the resulting connections would look like?
But back to your question. You need to choose the right technology for the right application. Graph databases are better suited in instances where you have to very rapidly traverse deep connections. They are “stupid fast” at that. Also, a graph data model is easier for most non-technical types to understand.
@Peter – This may be part of a different conversation, but the concept of ‘duplicate’ is one that has garnered a fair bit of discussion in my world. (I follow Henrik for his knowledge in that domain). It seems each of the platforms mentioned here manage duplicates differently, but at bottom any system needs at least three intersecting data points – none of which are IDs – to confidently assert that one string/label/name is unique from any other string/label/name.
If my Master Data has 21 instances of ‘International Commerce Society’ I had better be able to confidently assert their existence as 21 individual entities or, as you point out, chaos ensues. In a related use case, I should also be able to assert that ‘ICS’ is equivalent to at least one of those 21 and I must also be able to assert that ‘SCI’ is the French language acronym equivalent of ‘Société de Commerce International’
There are advantages (and offsetting costs) in each of the platforms mentioned here, but in my view the best place to test, validate and assert individuality (i.e. identity) is in the MDM domain.
Thanks for commenting Peter. Good points. And indeed I see an opportunity for expanding the “stupid fast” way of graph tech with some identity resolution based on more traditional external reference data.
No, Graph databases are an attempt at “associative database technology” and poorly done at that.. Big Data is marketing term, plain and simple. . as Dr Tang said, “the present solution is to wrap up a bunch of bottle rockets (SQL, Hadoop, Cassandra, Mongo, couch etc)and call it a jet engine.. ” LOL one more term, we don’t change the Science named ASTRONOMY to “Big Stars” simply because we find more of them.. 😉
Assume instead you were able to de-duplicate each and every piece of data entered into a system and require only 4 reads for any piece or pieces of information and that information already be in context? Given this possibility, there are only 64,000 or so symbols for communications in the Human civilization.. assuming a 4Byte array as standard, you get a maximum physical data storage requirement of 1.6 to the 19th 160 exabyte.. quadruple that for associations and context and you are at about give or take 800 exabyte for all the knowledge on this planet to date.. now assume this is not available to you , well there are not enough computers and or storage to support this effort let alone a method of retrieving any kind of useful information in a timely and cost effective manner. so the long term prospect of Graph , Cassandra, MONGO, Hadoop et al. is limited at best.. NEW SCIENCE is required not repackaged relabeled horse and buggy technology
NEW Science does now exist, and can accommodate anything your mind can create or come up with, and can install on any device on this planet including computers, sensors, phones, car, planes, trains, refrigerators , traffic lights etc.. ..
Welcome to the Future.. (http://www.youtube.com/watch?v=DeExbclijPg ) (last 15 min is live demo)