The TLAs (Three Letter Acronyms) in the title of this blog post stands for:
- Customer Data Integration
- Product Information Management
- Master Data Management
CDI and PIM are commonly seen as predecessors to MDM. For example, the MDM Institute was originally called the The Customer Data Integration Institute and still have this website: http://www.tcdii.com/.
Today Multi-Domain MDM is about managing customer, or rather party, master data together with product master data and other master data domains as visualized in the post A Master Data Mind Map. Some of the most frequent other master domains are location master data and asset master data, where the latter one was explored in the post Where is the Asset? A less frequent master data domain is The Calendar MDM Domain.
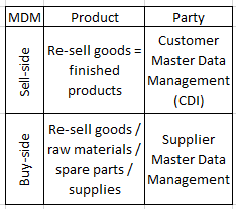 You may argue that PIM (Product Information Management) is not the same as Product MDM. This question was examined in the post PIM, Product MDM and Multi-Domain MDM. In my eyes the benefits of keeping PIM as part of Multi-Domain MDM are bigger than the benefits of separating PIM and MDM. It is about expanding MDM across the sell-side and the buy-side of the business eventually by enabling wide use of customer self-service and supplier self-service.
You may argue that PIM (Product Information Management) is not the same as Product MDM. This question was examined in the post PIM, Product MDM and Multi-Domain MDM. In my eyes the benefits of keeping PIM as part of Multi-Domain MDM are bigger than the benefits of separating PIM and MDM. It is about expanding MDM across the sell-side and the buy-side of the business eventually by enabling wide use of customer self-service and supplier self-service.
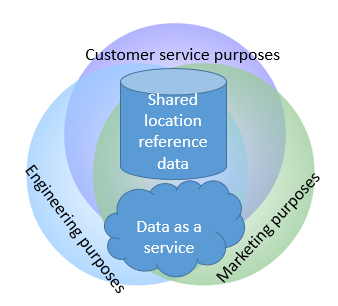
The external self-service theme will in my eyes be at the centre of where MDM is going in the future. In going down that path there will be consequences for how we see data governance as discussed in the post Data Governance in the Self-Service Age. Another aspect of how MDM is going to be seen from the outside and in is the increased use of third party reference data and the link between big data and MDM as touched in the post Adding 180 Degrees to MDM.
Besides Multi-Domain MDM and the links between MDM and big data a much mentioned future trend in MDM is doing MDM in the cloud. The latter is in my eyes a natural consequence of the external self-service themes and increased use of third party reference data which all together with the general benefits of the SaaS (Software as a Service) and DaaS (Data as a Service) concepts will make MDM morph into something like MDaaS (Master Data as a Service) – an at least nearly ten year old idea by the way, as seen in this BeyeNetwork article by Dan E Linstedt.
![]()
 Many CRM applications have the concepts of leads, accounts and contacts for registering customers or other parties with roles in sales and customer service.
Many CRM applications have the concepts of leads, accounts and contacts for registering customers or other parties with roles in sales and customer service. Business directories:
Business directories: During the two days a lot of ideas for how to exploit open public sector data within the private sector were put on the table. I was so lucky to win a SmartWatch as being part of the group with the winning concept that is a service for identifying buildings with potential for energy saving improvements. This service will be of benefit for both large enterprises as building material manufacturers (and in fact energy suppliers), local small and midsize businesses, the house owners and the society as a whole in order to fulfil climate change prevention goals.
During the two days a lot of ideas for how to exploit open public sector data within the private sector were put on the table. I was so lucky to win a SmartWatch as being part of the group with the winning concept that is a service for identifying buildings with potential for energy saving improvements. This service will be of benefit for both large enterprises as building material manufacturers (and in fact energy suppliers), local small and midsize businesses, the house owners and the society as a whole in order to fulfil climate change prevention goals. Being too late was unfortunately also the case as examined in the article
Being too late was unfortunately also the case as examined in the article  External data supports data quality improvement and prevention of party master data by:
External data supports data quality improvement and prevention of party master data by: