Yesterday we had a call from British Gas (or probably a call centre hired by British Gas) explaining the great savings possible if switching from the current provider – which by the way is: British Gas. This is a classic data quality issue in direct marketing operations being accurately separating your current customers and entities belonging to new market.
As I have learned that your premier identity proof in the United Kingdom is your utility bill, this incident may be seen as somewhat disturbing – or by further thinking, maybe a business opportunity 🙂
At iDQ we develop a solution that may be positioned in the space between data quality prevention and identity check by addressing the identity resolution aspect during data capture.
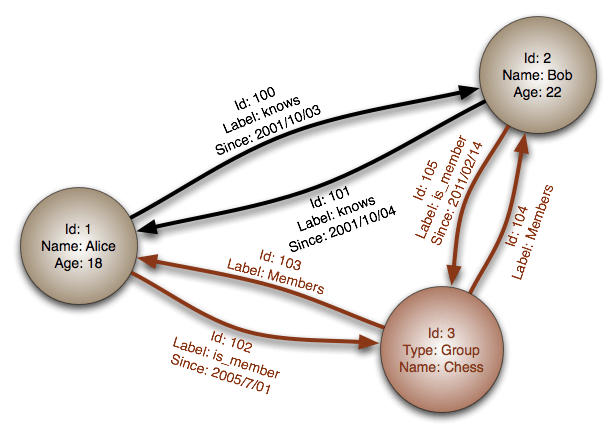
In MDM (Master Data Management) there is the term Multi-Domain MDM being how we manage respectively parties, products, locations and other entity types and handling master data within a Multi-Channel environment encompassing offline, online and social channels is a huge challenge within MDM today. Yet another multi view of MDM is handling different facets of master data being:
Entities
Relations
Events
Entities
Handling entities is the core of master data management. Ensuring that master data are fit for multiple purposes most often by ensuring real world alignment is the basic goal of master data management. Entity resolution is at key discipline in doing that. In the party master data domain doing Customer Data Integration (CDI) is the good old activity aiming at compiling all the customer data silos in the enterprise into a golden copy with golden records. Product Information Management (PIM) is another ancestor in the MDM evolution history predominately focusing at the entities.
As we get better and better solutions for handling entities the innovation shifts to handling the relationships between entities. These relations exists for example in Multi-Channel environments by linking entities in the old systems of record with the same real world entities in the new systems of engagement as told in the post Social MDM and Systems of Engagement.
Events
Getting the master data right the first time is crucial.
In product master data management getting to that stage is often done by managing a flow of events where the product data are completed and approved by a team of knowledge workers.
In party master data management a way of ensuring first time right is examined in the post instant Single Customer View. But that is only the start. Party master data has a life cycle with important events as:
The party moves to a another location as explained in the post The Relocation Event
Babbling about data quality, real world alignment and maps is a regular topic on this blog and this Saturday is no exception.
This week I stumbled on a discussion in the “Data, Data, Data” community on Google Plus. There was a map:
The map visualizes how the world would look like if every internet user had an equal amount of space to live on. This turns the land masses on the earth to have a different shape than in reality given:
Population density
Internet penetration
As internet penetration is the main purpose of the map the penetration percentage for the different countries are highlighted by color in order to be fit for the purpose of use and thus showing highest penetration in Canada, Northern Europe, Qatar, South Korea and New Zealand.
Some countries seem to have disappeared from the planet as mentioned in the comments on Google Plus: Singapore, Taiwan (officially Republic of China) and North Korea (officially Democratic People’s Republic of Korea). The latter one has probably gone because of no data or no users. Well, probably both reasons.
On a side note it’s a bit peculiar that countries on the map are labeled by the ISO 3 character code and not the 2 character code that more resembles country domains on the internet.
18 years ago I cruised into the data quality realm when making my first deduplication tool. Then it was an attempt to solve a business case of two companies who were considering merging and wanted to know the intersection of customers. So far, so good.
Since then I have worked intensively with deduplication and other data matching tools and approaches and also co-authored a leading eLearning course on the matter as seen here.
Deduplication capability is a core feature of many data quality tools and indeed the probably most mentioned data quality pain is lack of uniqueness not at least in party master data management.
However, most deduplication efforts don’t in my experience stick. Yes, we can process a file ready for direct marketing and purge the messages that might end up in the same offline or online inbox despite of spelling differences. But taking it from there and use the techniques in achieving a single customer view is another story. Some obstacles are:
In the comments to the latter 3 year old post the intersection (and non-intersection) of Entity Resolution and Master Data Management (MDM) was discussed.
During my latest work I have become more and more convinced that achieving a single view of something is a lot about entity resolution as expressed in the post The Good, Better and Best Way of Avoiding Duplicates.
One of my pet peeves in data quality for CRM and ERP systems is the often used way at looking at entities, not at least party entities, in a flat data model as told in the post A Place in Time.
Party master data, and related location master data, will eventually be modeled in very complex models and surely we see more and more examples of that. For example I remember that I long time ago worked with the ERP system that later became Microsoft Dynamics AX. Then I had issues with the simplistic and not role aware data model. While I’m currently working in a project using the AX 2012 Address Book it’s good to see that things have certainly developed.
This blog has quite a few posts on hierarchy management in Master Data Management (MDM) and even Hierarchical Data Matching. But I have to admit that even complex relational data models and hierarchical approaches in fact don’t align completely with the real world.
I remember at this year’s MDM Summit Europe that Aaron Zornes suggested that a graph database will be the best choice for reflecting the most basic reference dataset being The Country List. Oh yes, and in master data too you should think then, though I doubt that the relational database and hierarchy management will be out of fashion for a while.
So it could be good to know if you have seen or worked with graph databases in master data management beyond representing a static analysis result as a graph database.
When maintaining party master data one of the challenges is to have the data about the physical address, and sometimes the physical addresses, of a registered party up to date.
You may learn about that your customer, supplier, employee or whatever party you are keeping on record has moved in many ways. Most common are:
The person or organization in question is so kind to tell you so. For some purposes for example in the utility sector this event is a future event that triggers a whole workflow of actions.
You get the message via a subscription to external reference data for example using available National Change of Address (NCOA) services and services related to business directories and citizen registries.
Your mail to a person or organization is returned from postal services often with no information about the new address, so this means investigation work ahead.
Capability to handle this important issue in party master data management (MDM) embracing all the above mentioned scenarios is essential for many enterprises and doing it on an international scale with the different sources and services available in different countries is indeed a daunting task.
Handling the relocation event is a core functionality in the master data service (iDQ™ MDM Edition) I’m currently working with. There’s lot to do in this quest, so I better move on.
The post has a good walk through on the topic and reaches this conclusion:
“So, which is better, Deterministic Matching or Probabilistic Matching? The question should actually be: ‘Which is better for you, for your specific needs?’ Your specific needs may even call for a combination of the two methodologies instead of going purely with one.”
On a side note the author of the post is MARIANITORRALBA. I had to use my combined probabilistic and deterministic in-word parsing supported and social media connected data matching capability to match this concatenated name with the Linked profile of an InfoTrellis employee called Marian Itorralba.
This little exercise brings me to an observation about data matching that is, that matching party master data, not at least when you do this for several purposes, ultimately is identity resolution as discussed in the post The New Year in Identity Resolution.
For that we need what could be called hierarchical data matching.
The reason we need hierarchical data matching is that more and more organizations are looking into master data management and then they realize that the classic name and address matching rules do not necessarily fit when party master data are going to be used for multiple purposes. What constitutes a duplicate in one context, like sending a direct mail, doesn’t necessary make a duplicate in another business function and vice versa. Duplicates come in hierarchies.
One example is a household. You probably don’t want to send two sets of the same material to a household, but you might want to engage in a 1-to-1 dialogue with the individual members. Another example is that you might do some very different kinds of business with the same legal entity. Financial risk management is the same, but different sales or purchase processes may require very different views.
This matter is discussed in the post and not at least the comments of the post called Hierarchical Data Matching.
A variant of the saying “Know Your Customer” for a football club will be “Know Your Fan” and indeed fans are customers when they buy tickets. If they can.
FC Copenhagen cruised into stormy waters when they apparently cancelled all purchases for the upcoming Champions League (European soccer club paramount tournament) clashes against Real Madrid, Juventus and Galatasaray if the purchasers didn’t have a Danish sounding name. The reason was to prevent mixing fans of the different clubs, but surely this poorly thought screening method wasn’t received well among the FC Copenhagen fans not called Jensen, Nielsen or Sørensen.
Yesterday on The Postcode Anywhere blog Guy Mucklow wrote a nice piece called University Challenge. The blog post is about challenges with shared addresses and a remedy at least for addresses in the United Kingdom.
And sure, I also had my challenges with a shared address in the UK as reported in the post Multi-Occupancy.
But I guess the University Challenge is a universal challenge.
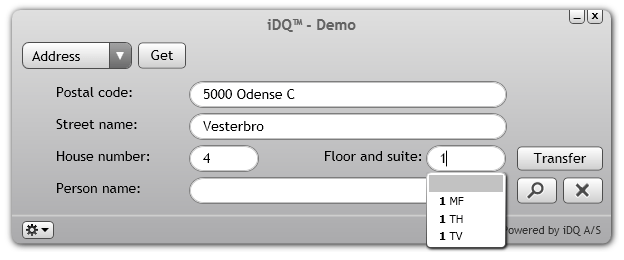
The postal formats and available reference data sources are of course very different around. Below is an example from the iDQ™ (instant Data Quality) tool when handling a Danish address with multiple flats. Here the tool continuously display what options is available to make the address unique:
As described in the post Small Data with Big Impact my guess is that we will see Master Data Management solutions as a core element in having data architectures that are able to make sustainable results from dealing with big data.
If we look at party master data a serious problem with many ERP and CRM systems around is that the data model for party master data aren’t good enough for dealing with the many different forms and differences in which the parties we hold data about are represented in big data sources which makes the linking between traditional systems of record and big data very hard.
Having a Master Data Management (MDM) solution with a comprehensive data model for party master data is essential here.
Some of the capabilities we need are:
Storing multiple occurrences of attributes
People and companies have many phone numbers, they have many eMail addresses and they have many social identities and you will for sure meet these different occurrences in big data sources. Relating these different occurrences to the same real world entity is essential as reported in the post 180 Degree Prospective Customer View isn’t Unusual.
An MDM hub with a corresponding data model is the place to manage that challenge in one place.
Exploiting rich external reference data
As told in the post Where the Streets have Two Names and emphasized in the comments to the post the real world has plenty of examples of the same thing having many names. And this real world will be reflected in big data sources.
Your MDM solution should embrace external reference data solving these issues.
Handling the time dimension
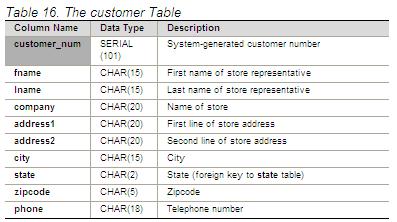
In the post A Place in Time the flaws of the usual customer table in ERP and CRM systems is examined. One common issue is handling when attributes changes. Change of address happens a lot. And this may be complicated by that we may operate several address types at the same time like visiting addresses, billing addresses and correspondence addresses. These different addresses will also pop up in big data sources. And the same goes for other attributes.
You must get that right in your MDM implementation.
The usual but very wrong customer table that wont work with big data.
 At iDQ we develop a solution that may be positioned in the space between data quality prevention and identity check by addressing the identity resolution aspect during data capture.
At iDQ we develop a solution that may be positioned in the space between data quality prevention and identity check by addressing the identity resolution aspect during data capture.