There are many signs showing that we are entering the age of business ecosystems. A recent example is an article from Digital McKinsey. This read worthy article is called Adopting an ecosystem view of business technology.
In here, the authors emphasizes on the need to adapt traditional IT functions to the opportunities and challenges of emerging technologies that embraces business ecosystems. I fully support that sentiment.
In my eyes, some of the emerging technologies we see are in large misunderstood as something meant for being behind the corporate walls. My favorite example is the data lake concept. I do not think a data lake will be an often seen success solely within a single company as explained in the post Data Lakes in Business Ecosystems.
The raise of technology for business ecosystems will also affect the data management roles we know today. For example, a data steward will be a lot more focused towards external data than before as elaborated in the post The Future of Data Stewardship.
Encompassing business ecosystems in data management is of course a huge challenge we have to face while most enterprises still have not reached an acceptable maturity when it comes internal data and information governance. However, letting the outside in will also help in getting data and information right as told in the post Data Sharing Is The Answer To A Single Version Of The Truth.

 The fear, and actual observations made, is that that a data lake will become a data dump. No one knows what is in there, where it came from, who is going to clean up the mess and eventually have a grip on how it should be handled in the future – if there is a future for the data lake concept.
The fear, and actual observations made, is that that a data lake will become a data dump. No one knows what is in there, where it came from, who is going to clean up the mess and eventually have a grip on how it should be handled in the future – if there is a future for the data lake concept.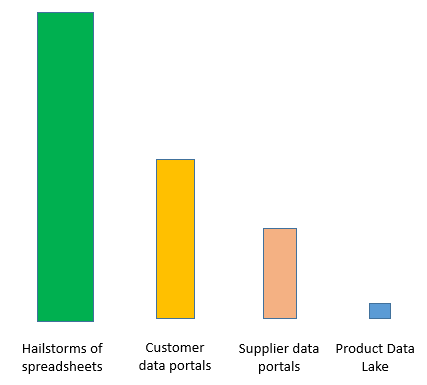
 However, there are good reasons to consider using the
However, there are good reasons to consider using the  Data Governance
Data Governance In
In  A pearl is a popular gemstone. Natural pearls, meaning they have occurred spontaneously in the wild, are very rare. Instead, most are farmed in fresh water and therefore by regulation used in many countries must be referred to as cultured freshwater pearls.
A pearl is a popular gemstone. Natural pearls, meaning they have occurred spontaneously in the wild, are very rare. Instead, most are farmed in fresh water and therefore by regulation used in many countries must be referred to as cultured freshwater pearls.
 When following the articles, blog posts and other inspirational stuff in the data management realm you frequently stumble upon sayings about a unique angle towards what it is all about, like:
When following the articles, blog posts and other inspirational stuff in the data management realm you frequently stumble upon sayings about a unique angle towards what it is all about, like: The anecdotal evidences with the highest weights are those included according to the HiPPO (Highest Paid Person’s Opinion) principle as examined in the post
The anecdotal evidences with the highest weights are those included according to the HiPPO (Highest Paid Person’s Opinion) principle as examined in the post 
{kind=link}