Merchants sells the goods produced by manufacturers. In that game merchants and manufacturers are basically allies. Then of course the merchant’s profit may depend on the margin he can get between the manufacturers price to him and the merchant’s price to his customer. In that game, merchants and manufacturers are kind of enemies.
When it comes to providing product information to the end customers, merchants and manufacturers are allies too. The more complete product information placed in front of the end customer, the better. This is increasingly important today with more and more goods sold in self-service scenarios as in ecommerce.
 But again, there seems to be an enemy angle here too. Who should have the burden of lifting product information as the manufacturers have it to the way it is presented at the point-of-sales provided by the merchant? Often this seems to be stalled in a standoff as described in the post Passive vs Active Product Information Exchange.
But again, there seems to be an enemy angle here too. Who should have the burden of lifting product information as the manufacturers have it to the way it is presented at the point-of-sales provided by the merchant? Often this seems to be stalled in a standoff as described in the post Passive vs Active Product Information Exchange.
At Product Data Lake we offer merchants and manufacturers an honorable way out of this standoff:
- As a merchant, you can utilize our Product Data Pull service
- As a manufacturer, you can utilize our Product Data Push service
 The title of this blog post is the title of, in my rapid eye movements, one the best albums ever:
The title of this blog post is the title of, in my rapid eye movements, one the best albums ever: 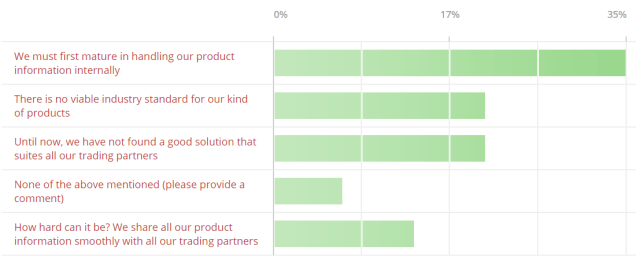
 “Organisations need architectural thinking beyond their organisational boundaries” and “The days of Enterprise Architecture taking a castle and moat approach are over”.
“Organisations need architectural thinking beyond their organisational boundaries” and “The days of Enterprise Architecture taking a castle and moat approach are over”. Solving this issue is one of the things we do at Liliendahl.com. Besides being an advisory service in the Master Data Management (MDM) and Product Information Management (PIM) space, we have a developing collaboration with companies providing consultancy, cleansing and, when you come to that step, specialized technology for inhouse MDM and PIM. Take a look at
Solving this issue is one of the things we do at Liliendahl.com. Besides being an advisory service in the Master Data Management (MDM) and Product Information Management (PIM) space, we have a developing collaboration with companies providing consultancy, cleansing and, when you come to that step, specialized technology for inhouse MDM and PIM. Take a look at  I am sorry to say that I think that using a PIM vendor (or supplier) portal is like lipstick on a pig.
I am sorry to say that I think that using a PIM vendor (or supplier) portal is like lipstick on a pig.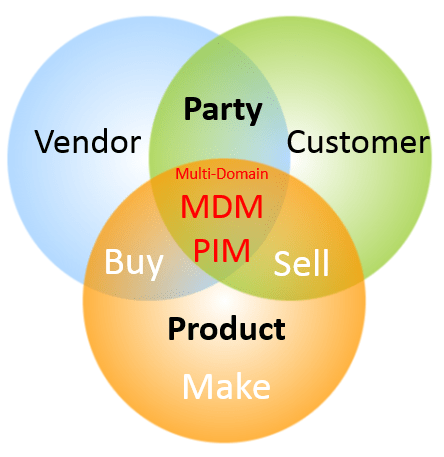
 Another concept, which is the opposite, is also emerging. This is manufacturers and upstream distributors establishing PIM customer portals, where suppliers can fetch product information. This concept is in my eyes flawed exactly the opposite way.
Another concept, which is the opposite, is also emerging. This is manufacturers and upstream distributors establishing PIM customer portals, where suppliers can fetch product information. This concept is in my eyes flawed exactly the opposite way.