One of the most promising aspects of digitalization is sharing information in business ecosystems. In the Master Data Management (MDM) realm, we will in my eyes see a dramatic increase in sharing product information between trading partners as touched in the post Data Quality 3.0 as a stepping-stone on the path to Industry 4.0.
Standardization (or standardisation)
A challenge in doing that is how we link the different ways of handling product information within each organization in business ecosystems. While everyone agrees that a common standard is the best answer we must on the other hand accept, that using a common standard for every kind of product and every piece of information needed is quite utopic. We haven’t even a common uniquely spelled term in English.
Also, we must foresee that one organization will mature in a different pace than another organisation in the same business ecosystem.
Product Data Lake
These observations are the reasons behind the launch of Product Data Lake. In Product Data Lake we encompass the use of (in prioritized order):
- The same standard in the same version
- The same standard in different versions
- Different standards
- No standards
In order to link the product information and the formats and structures at two trading partners, we support the following approaches:
- Automation based on product information tagged with a standard as explained in the post Connecting Product Information.
- Ambassadorship, which is a role taken by a product information professional, who collaborates with the upstream and downstream trading partner in linking the product information. Read more about becoming a Product Data Lake ambassador here.
- Upstream responsibility. Here the upstream trading partner makes the linking in Product Data Lake.
- Downstream responsibility. Here the downstream trading partner makes the linking in Product Data Lake.
 Data Governance
Data Governance
Regardless of the mix of the above approaches, you will need a cross company data governance framework to control the standards used and the rules that applies to the exchange of product information with your trading partners. Product Data Lake have established a partnership with one of the most recommended authorities in data governance: Nicola Askham – the Data Governance Coach.
For a quick overview please have a look at the Cross Company Data Governance Framework.
Please request more information here.
![]()
 In
In  Become a:
Become a: Agility is a good thing, but of course, you have to put some control on top of it as reported in the post
Agility is a good thing, but of course, you have to put some control on top of it as reported in the post 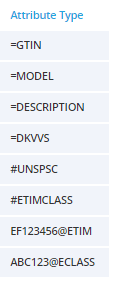 The Product Data Lake tagging approach
The Product Data Lake tagging approach



 But the market analysis and the trends observed is good stuff as well.
But the market analysis and the trends observed is good stuff as well.
{kind=link}