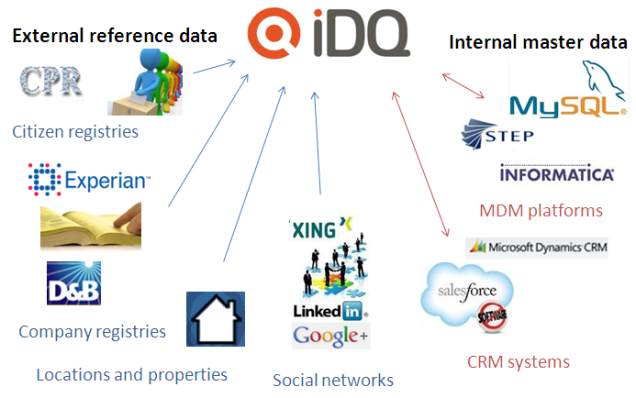
You can find many great analogies for working with data quality and Master Data Management (MDM) in world maps. One example is reported in the post The Greenland Problem in MDM, which is about how different business units have a different look on the same real world entity.
Real world alignment isn’t of course without challenges. Also because the real world changes as reported on Daily Mail in an article about how modern countries would be placed on the landmasses as they were 300 million years ago.
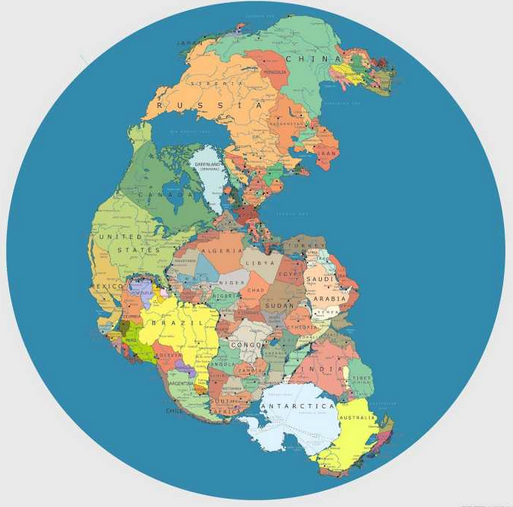
The image above may very well show how many master data repositories today reflect the real world. Yep, we may have the country list covered well enough. We may even do quite well if we look at each geographical unit independently. However, the big picture doesn’t fit the world as it is today.
![]()