Making vertical MDM (Master Data Management) solutions, being MDM solutions prepared for a given industry, seems to become a trend in the MDM realm.
Traditionally many MDM solutions actually are strong in a given industry or a few related industries.
This is also true for the MDM solution I’m working with right now, as this solution has gained traction in the utility sector.
So, what’s special (and not entirely special) about the utility sector?
Here are three of my observations:
Exploiting big external reference data
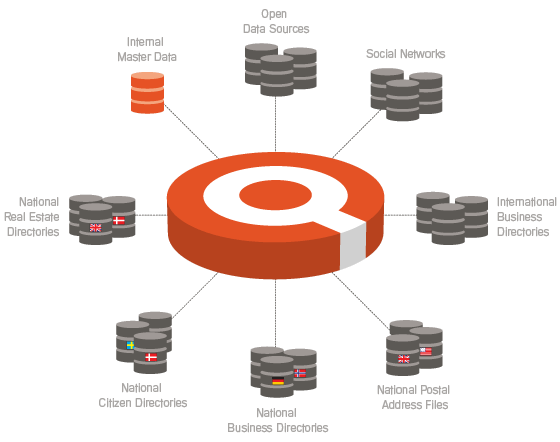
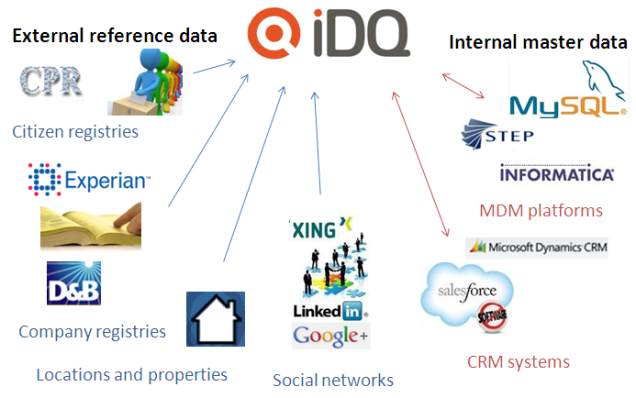
As examined in the post instant Data Quality at Work the utility sector may gain much in using all the available external reference data available in the party master data domain, including:
- Consumer/citizen directories
- Business directories
- Address directories
- Property directories
However, if data quality shouldn’t be a joke, this means using the best national data sources available as many of the world-wide data sources is this domain are far from providing the precision, accuracy and timeliness needed in the utility sector.
Location precision
Managing locations is a big thing in the utility sector. The post called Where is the Spot explains how identifying locations isn’t as simple as we may use to think in daily life.
This is indeed also true in the utility sector where the issue also includes managing many different locations for the same customer fulfilling different purposes at the same time.
The products
 The electricity supply part of the utility sector share a lot of issues with the telco sector when it comes to fixed installations and the products and services are in fact the same in some cases which also as a consequence means that some organizations belongs to both sectors.
The electricity supply part of the utility sector share a lot of issues with the telco sector when it comes to fixed installations and the products and services are in fact the same in some cases which also as a consequence means that some organizations belongs to both sectors.
This is also a danger with vertical MDM solutions as there may be several best-of-breed options for a given organization, which eventually will result in choosing more than one platform and thereby introducing the silos which MDM in first place was supposed to eliminate.
56.085053
12.439756