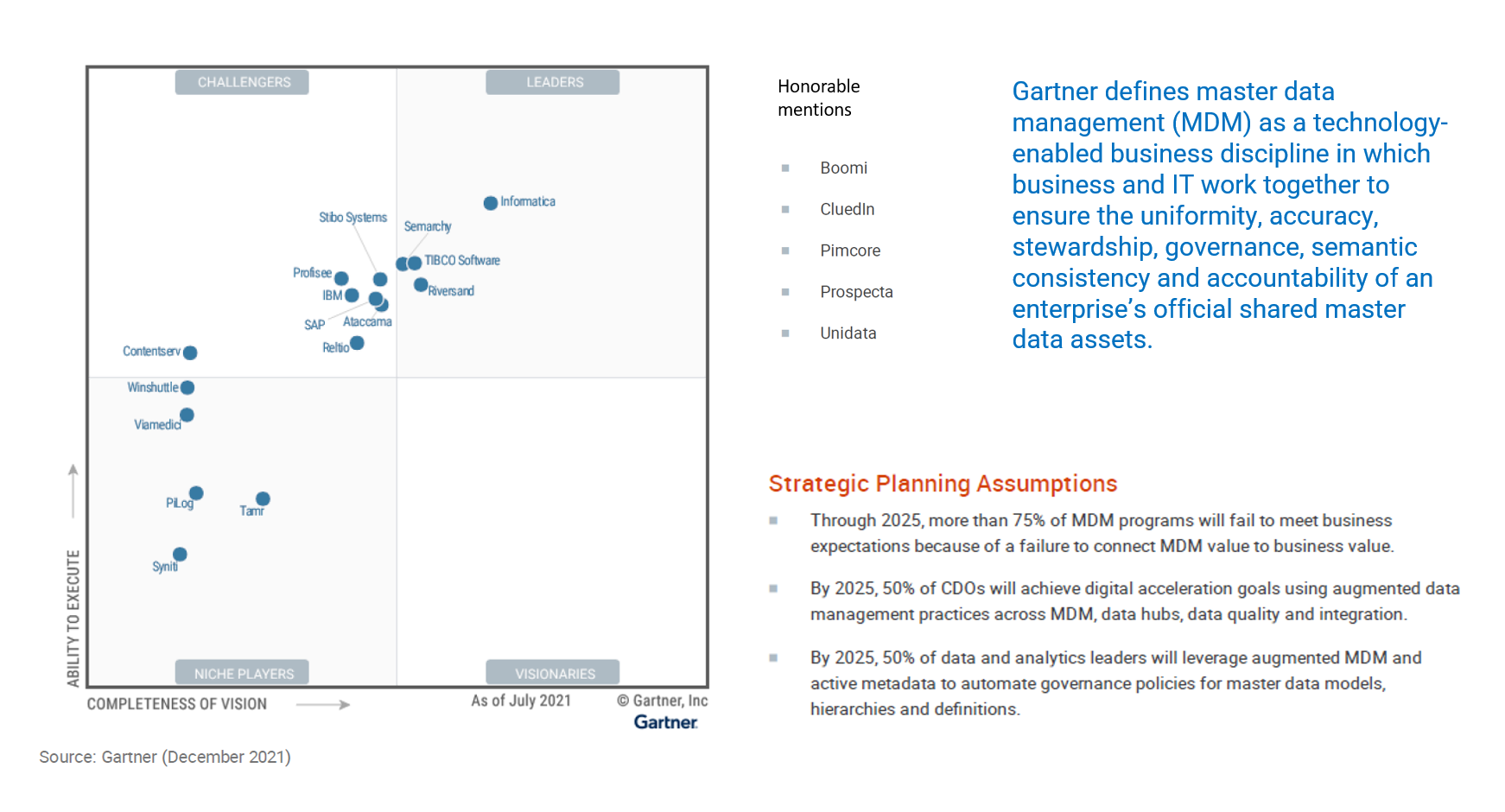
Some months ago, Gartner published the latest Hype Cycle for Digital Business Capabilities.
The hype cycle includes 4 concepts that in my mind will shape the future of Master Data Management (MDM) and data management in all. These are:
- Industrie 4.0
- Business Ecosystems
- Digital Twin
- Machine Customer
Industrie 4.0
You will find Industrie 4.0 near the trough of disillusionment almost ready to climb the slope of enlighten. Several of the recent MDM blue prints I have worked with have Industrie 4.0 as an overarching theme.
Industrie 4.0 is about using intelligent devices in manufacturing and thus closely connected to the term Industrial Internet of Things (IIoT). The impact of industry 4.0 is across the whole supply chain encompassing not only product manufacturing companies but also for example product merchants and product service providers.
With intelligent devices in the supply chain product MDM will evolve from handling data about product models to handle data about each instance of a product.
Business Ecosystems
The concept of business ecosystems has just passed the peak of inflated expectations.
In a modern business environment, no organization can do everything – or even most things – themselves. Therefore, any enterprise needs to partner with other organizations when working on new digital powered business models.
This also calls for increasing sharing of data, including master data, with business partners. This leads to the rise of interenterprise MDM, which by the way is at about the same position in the Hype Cycle for Data Analytics and MDM.
An example of interenterprise data sharing is Product Data Syndication.

Digital Twin
On the climbing side of the peak of inflated expectations we find the concept of a digital twin.
A digital twin is a virtual representation of a real-world entity such as an asset, person, organization, or process. This fits somehow with what MDM is doing which traditionally has been providing virtual descriptions of customers, suppliers, and products.
With the digital twin flavour, you can sharpen and extend MDM in two ways:
- Have a more real-world on customers and suppliers by looking at those has roles of business partners along with handling many other external and internal organizational entities
- Putting more asset types than direct products under the MDM umbrella with improved data governance as a result
Machine Customers
A bit further down the climbing side of the peak you will see the concept of the machine customer.
The expectation is that more and more buying tasks will be automated so there will be no human interaction in the bulk of purchasing processes.
This will only be possible if the products involved at those who sell them are digitally described in sufficient details and categorized the same way on the selling and buying side.
This seems like a job for Master Data Management and the adjacent Product Information Management (PIM) discipline where the buying side needs the right capabilities not only for direct trading products but also indirect supplies.
Also, the concept of augmented MDM will play a role here by applying Artificial Intelligence (AI) to the MDM and PIM side of enabling the machine customer.
The Full Report
You can download the full hype cycle report including the complete visual cycle from the parsionate website: Gartner Hype Cycle for Digital Business Capabilities.