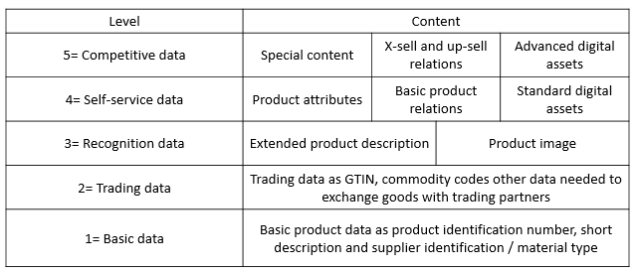
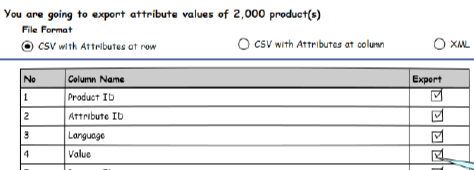
The term data lake has become popular along with the raise of big data. A data lake is a new of way of storing data that is more agile than what we have been used to in data warehouses. This is mainly based on the principle that you should not have thought through every way of consuming data before storing the data.
This agility is also the main reason for fear around data lakes. Possible lack of control and standardization leads to warnings about that a data lake will quickly develop into a data swamp.
 In my eyes we need solutions build on the data lake concept if we want business agility – and we do want that. But I also believe that we need to put data in data lakes in context.
In my eyes we need solutions build on the data lake concept if we want business agility – and we do want that. But I also believe that we need to put data in data lakes in context.
Fortunately, there are many examples of movements in that direction. A recent article called The Informed Data Lake: Beyond Metadata by Neil Raden has a lot of good arguments around a better context driven approach to data lakes.
As reported in the post Multi-Domain MDM 360 and an Intelligent Data Lake the data management vendor Informatica is on that track too.
In all humbleness, my vision for data lakes is that a context driven data lake can serve purposes beyond analytical use within a single company and become a driver for business agility within business ecosystems like cross company supply chains as expressed in the LinkedIn Pulse post called Data Lakes in Business Ecosystems.
![]()
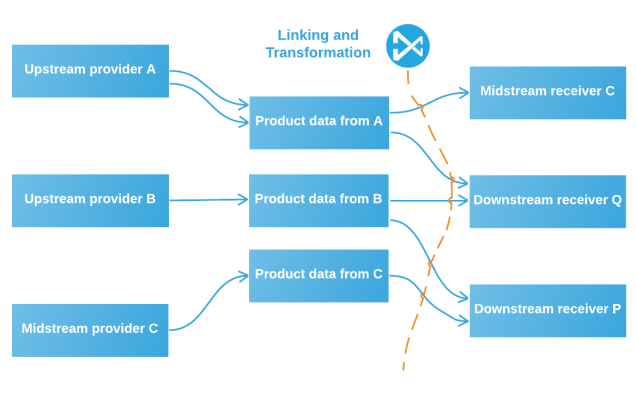
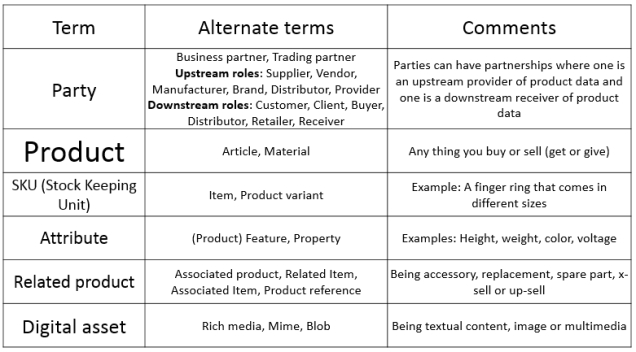

 All these solutions constitutes one of the leading Multi-Domain MDM offerings on the market – if not the leading. We will be wiser on that question when Gartner (the analyst firm) makes their first Multi-Domain MDM Magic Quadrant later this year as reported in the post
All these solutions constitutes one of the leading Multi-Domain MDM offerings on the market – if not the leading. We will be wiser on that question when Gartner (the analyst firm) makes their first Multi-Domain MDM Magic Quadrant later this year as reported in the post  Using third party data for customer and supplier master data seems to be a very good idea as exemplified in the post
Using third party data for customer and supplier master data seems to be a very good idea as exemplified in the post  When selecting an identifier there are different options as national IDs, LEI, DUNS Number and others as explained in the post
When selecting an identifier there are different options as national IDs, LEI, DUNS Number and others as explained in the post