The term golden record is a core concept within Master Data Management (MDM). A golden record is a representation of a real world entity that may be compiled from multiple different representations of that entity in a single or in multiple different databases within the enterprise system landscape.
 In Multi-domain MDM we work with a range of different entity types as party (with customer, supplier, employee and other roles), location, product and asset. The golden record concept applies to all of these entity types, but in slightly different ways.
In Multi-domain MDM we work with a range of different entity types as party (with customer, supplier, employee and other roles), location, product and asset. The golden record concept applies to all of these entity types, but in slightly different ways.
Party Golden Records
Having a golden record that facilitates a single view of customer is probably the most known example of using the golden record concept. Managing customer records and dealing with duplicates of those is the most frequent data quality issue around.
If you are not able to prevent duplicate records from entering your MDM world, which is the best approach, then you have to apply data matching capabilities. When identifying a duplicate you must be able to intelligently merge any conflicting views into a golden record.
In lesser degree we see the same challenges in getting a single view of suppliers and, which is one of my favourite subjects, you ultimately will want to have a single view on any business partner, also where the same real world entity have both customer, supplier and other roles to your organization.
Location Golden Records
Having the same location only represented once in a golden record and applying any party, product and asset record, and ultimately golden record, to that record may be seen as quite academic. Nevertheless, striving for that concept will solve many data quality conundrums.
Location management have different meanings and importance for different industries. One example is that a brewery makes business with the legal entity (party) that owns a bar, café, restaurant. However, even though the owner of that place changes, which happens a lot, the brewery is still interested in being the brand served at that place. Also, the brewery wants to keep records of logistics around that place and the historic volumes delivered to that place. Utility and insurance is other examples of industries where the location golden record (should) matter a lot.
Knowing the properties of a location also supports the party deduplication process. For example, if you have two records with the name “John Smith” on the same address, the probability of that being the same real world entity is dependent on whether that location is a single-family house or a nursing home.
Product Golden Record
Product Information Management (PIM) solutions became popular with the raise of multi-channel where having the same representation of a product in offline and online channels is essential. The self-service approach in online sales also drew the requirements of managing a lot more product attributes than seen before, which again points to a solution of handling the product entity centralized.
In large organizations that have many business units around the world you struggle with having a local view and a global view of products. A given product may be a finished product to one unit but a raw material to another unit. Even a global SAP rollout will usually not clarify this – rather the contrary.
While third party reference data helps a lot with handling golden records for party and location, this is lesser the case for product master data. Classification systems and data pools do exist, but will certainly not take you all the way. With product master data we must, in my eyes, rely more on second party master data meaning sharing product master data within the business ecosystems where you are present.
Asset (or Thing) Golden Records
In asset master data management you also have different purposes where having a single view of a real world asset helps a lot. There are namely financial purposes and logistic purposes that have to aligned, but also a lot of others purposes depending on the industry and the type of asset.
With the raise of the Internet of Things (IoT) we will have to manage a lot more assets (or things) than we usually have considered. When a thing (a machine, a vehicle, an appliance) becomes intelligent and now produces big data, master data management and indeed multi-domain master data management becomes imperative.
You will want to know a lot about the product model of the thing in order to make sense of the produced big data. For that, you need the product (model) golden record. You will want to have deep knowledge of the location in time of the thing. You cannot do that without the location golden records. You will want to know the different party roles in time related to the thing. The owner, the operator, the maintainer. If you want to avoid chaos, you need party golden records.
 While this quote rightfully emphasizes on that a lot of money is at stake, the quote itself holds a full load of data and information quality issues.
While this quote rightfully emphasizes on that a lot of money is at stake, the quote itself holds a full load of data and information quality issues. Whether you are a company participating in a cross company supply chain or you help your clients in doing that, you can help us to help you by taking this
Whether you are a company participating in a cross company supply chain or you help your clients in doing that, you can help us to help you by taking this 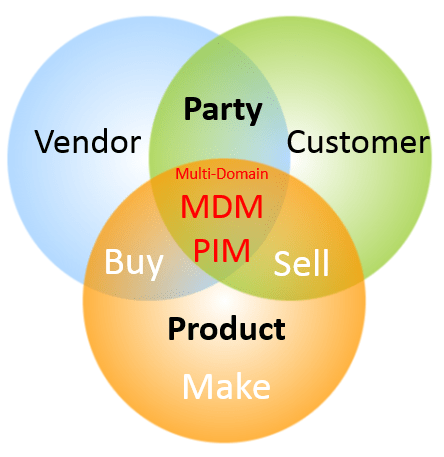





 Another concept, which is the opposite, is also emerging. This is manufacturers and upstream distributors establishing PIM customer portals, where suppliers can fetch product information. This concept is in my eyes flawed exactly the opposite way.
Another concept, which is the opposite, is also emerging. This is manufacturers and upstream distributors establishing PIM customer portals, where suppliers can fetch product information. This concept is in my eyes flawed exactly the opposite way.