Disciplines come and go in the data management world. Here is a mind map of the disciplines on top of my mind today. Some of the disciplines goes back to the emerge of IT in the previous millennium and some have risen during the latest years.

Disciplines come and go in the data management world. Here is a mind map of the disciplines on top of my mind today. Some of the disciplines goes back to the emerge of IT in the previous millennium and some have risen during the latest years.
In the recent Gartner Magic Quadrant for Master Data Management Solutions there is a bold statement:
“By 2023, organizations with shared ontology, semantics, governance and stewardship processes to enable interenterprise data sharing will outperform those that don’t.“
The interenterprise data sharing theme was covered a couple of years ago here on the blog in the post What is Interenterprise Data Sharing?
Interenterprise data sharing must be leveraged through interenterprise MDM, where master data are shared between many companies as for example in supply chains. The evolution of interenterprise MDM and the current state of the discipline was touched in the post MDM Terms In and Out of The Gartner 2020 Hype Cycle.
In the 00’s the evolution of Master Data Management (MDM) started with single domain / departmental solutions dominated by Customer Data Integration (CDI) and Product Information Management (PIM) implementations. These solutions were in best cases underpinned by third party data sources as business directories as for example the Dun & Bradstreet (D&B) world base and second party product information sources as for example the GS1 Global Data Syndication Network (GDSN).
In the previous decade multidomain MDM with enterprise-wide coverage became the norm. Here the solution typically encompasses customer-, vendor/supplier-, product- and asset master data. Increasingly GDSN is supplemented by other forms of Product Data Syndication (PDS). Third party and second party sources are delivered in the form of Data as a Service that comes with each MDM solution.

In this decade we will see the rise of interenterprise MDM where the solutions to some extend become business ecosystem wide, meaning that you will increasingly share master data and possibly the MDM solutions with your business partners – or else you will fade in the wake of the overwhelming data load you will have to handle yourself.
So, watch out for not applying interenterprise MDM.
PS: That goes for MDM end user organizations and MDM platform vendors as well.
The term “contextual Master Data Management” has been floating around in a couple of years as for example when tool vendors want to emphasize on a speciality that they are very good at. One example is from the Data Quality Management leader Precisely in the August 2020 article with the title How Contextual MDM Drives True Results in the Age of Data Democratization. Another example is from the Product Information/Experience Management leader Contentserv in the 2017 article with the title Contentserv Expands its Portfolio with Innovative Contextual MDM.
We can see contextual MDM as smaller pieces of MDM with a given flavour as for example focussing on sub/overlapping disciplines as:
The focus can also be at:
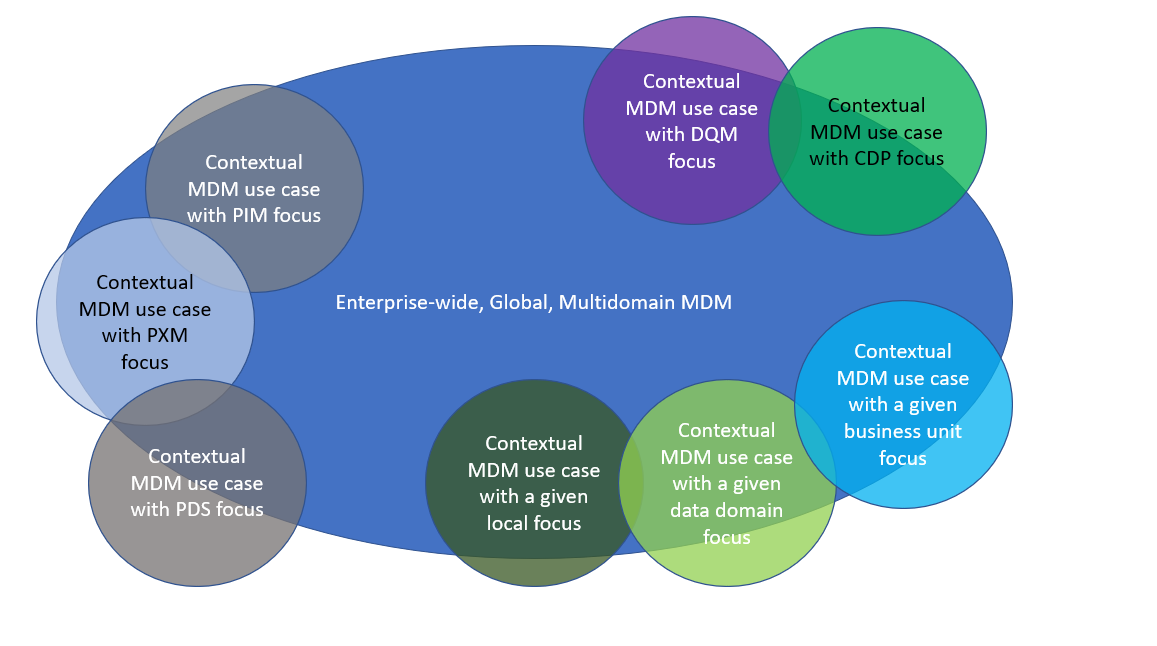
You must eat an elephant one bite at a time. Therefore, contextual MDM makes a good concept for getting achievable wins.
However, in an organization with high level of data management maturity the range of contextual MDM use cases, and the solutions for them, will be encompassed by a common enterprise-wide, global, multidomain MDM framework – either as one solution or a well-orchestrated set of solutions.
One example with dependencies is when working with personalization as part of Product Experience Management (PXM). Here you need customer personas. The elephant in the room, so to speak, is that you have to get the actual personas from Customer MDM and/or the Customer Data Platform (CDP).
In having that common MDM solution/framework there are some challenges to be solved in order to cater for all the contextual MDM use cases. One such challenge, being context-aware customer views, was touched upon in the post There is No Single Customer 360 View.
In today’s experience economy and in the age of digital transformation, there are two distinct ways you can use modern master data management to drive positive business outcomes:
As customer centricity is vital to any digitisation project, so it must follow that improving the customer experience (CX) is a key objective of any digital transformation project.
Getting a comprehensive 360-degree view of customers in digital business processes involves the ability to connect customer master data with other master data entities, hierarchies, transactions, big data, and reference data.

As the diagram above shows, a connected and extended master data landscape (aka data hub) will give you the essential capabilities you need in order to understand your customers. Knowing your customers better allows you to develop better products, drive new streams of revenue, and deliver the best customer experience through hyper-personalization.
Learn more in the white paper co-authored by Reltio and yours truly: Taking Customer 360 to The Next Level: Fueling New Digital Business

The saying in the title of this blog post is taken from a recent Gartner article with the tile Data Sharing Is a Business Necessity to Accelerate Digital Business.
In this article authored by Laurence Goasduff a key takeaway is that:
‘By 2023, organizations that promote data sharing will outperform their peers on most business value metrics”.
Regular readers of this blog will know that many good data things come from data sharing as for example pondered in the 11 years old post called Sharing data is key to a single version of the truth.
A consequence of the business benefits in sharing data will be a rise in data management disciplines aiming at business ecosystem wide data sharing, where product data syndication is an obvious opportunity.
During the last years I have been working on such a solution. This one is called Product Data Lake.

McKinsey Digital recently published an article with the title How do companies create value from digital ecosystems?
In here it is said that: “The integrated network economy could represent a global revenue pool of $60 trillion in 2025 with a potential increase in total economy share from about 1 to 2 percent today to approximately 30 percent by 2025”.
This dramatic shift will in my eyes mean a change of direction in the way we see Master Data Management (MDM) as well as Product Information Management (PIM) and Data Quality Management (DQM) solutions.
360 is a magic number in the master data and data quality world. It is about having a 360-degree view of customers, suppliers, and products. This is an inside-out view. The enterprise is looking at a world revolving around the enterprise just as back then when we thought the universe revolved around the planet Earth.
By 2025 forward looking enterprises must have changed that view and directed master data, product information and data quality management into a state fit for the network economy by having a business ecosystem wide MDM (PIM and DQM) solution landscape.
Gartner, the analyst firm, coins this Multienterprise MDM.
In the recent Gartner Top 10 Trends in Data and Analytics for 2020 trend number 8 is about data marketplaces and exchanges. As stated by Gartner: “By 2022, 35% of large organizations will be either sellers or buyers of data via formal online data marketplaces, up from 25% in 2020.”
The topic of selling and buying data was touched here on the blog in the post Three Flavors of Data Monetization
A close topic to data marketplaces and exchanges is Multienterprise MDM.
In the 00’s the evolution of Master Data Management (MDM) started with single domain / departmental solutions dominated by Customer Data Integration (CDI) and Product Information Management (PIM) implementations. These solutions were in best cases underpinned by third party data sources as business directories as for example the Dun & Bradstreet (D&B) world base and second party product information sources as for example the GS1 Global Data Syndication Network (GDSN).
In the previous decade multidomain MDM with enterprise wide coverage became the norm. Here the solution typically encompasses customer-, vendor/supplier-, product- and asset master data. Increasingly GDSN is supplemented by other forms of Product Data Syndication (PDS). Third party and second party sources are delivered in the form of Data as a Service that comes with each MDM solution.

In this decade we will see the rise of multienterprise MDM where the solutions to some extend become business ecosystem wide, meaning that you will increasingly share master data and possibly the MDM solutions with your business partners – or else you will fade in the wake of the overwhelming data load you will have to handle yourself.
The data sharing will be facilitated by data marketplaces and exchanges.
On July 23rd I will, as a representative of The Disruptive MDM/PIM/DQM List, present in the webinar How to Sustain Digital Ecosystems with Multi-Enterprise MDM. The webinar is brought to you by Winshuttle / Enterworks. It is a part of their everything MDM & PIM virtual conference. Get the details and make your free registration here.
The Business-to-Business-to-Consumer (B2B2C) scenario is increasingly important in Master Data Management (MDM), Product Information Management (PIM) and Data Quality Management (DQM).
This scenario is usually seen in manufacturing including pharmaceuticals as examined in the post Six MDMographic Stereotypes.
One challenge here is how to extend the capabilities in MDM / PIM / DQM solutions that are build for Business-to-Business (B2B) and Business-to-Consumer (B2C) use cases. Doing B2B2C requires a Multidomain MDM approach with solid PIM and DQM elements either as one solution, a suite of solutions or as a wisely assembled set of best-of-breed solutions. In the MDM sphere a key challenge with B2B2C is that you probably must encompass more surrounding applications and ensure a 360-degree view of party, location and product entities as they have varying roles with varying purposes at varying times tracked by these applications. You will also need to cover a broader range of data types that goes beyond what is traditionally seen as master data.
In the MDM sphere a key challenge with B2B2C is that you probably must encompass more surrounding applications and ensure a 360-degree view of party, location and product entities as they have varying roles with varying purposes at varying times tracked by these applications. You will also need to cover a broader range of data types that goes beyond what is traditionally seen as master data.
In DQM you need data matching capabilities that can identify and compare both real-world persons, organizations and the grey zone of persons in professional roles. You need DQM of a deep hierarchy of location data and you need to profile product data completeness for both professional use cases and consumer use cases.
In PIM the content must be suitable for both the professional audience and the end consumers. The issues in achieving this stretch over having a flexible in-house PIM solution and a comprehensive outbound Product Data Syndication (PDS) setup.
As the middle B in B2B2C supply chains you must have a strategic partnership with your suppliers/vendors with a comprehensive inbound Product Data Syndication (PDS) setup and increasingly also a framework for sharing customer master data taking into account the privacy and confidentiality aspects of this.
This emerging MDM / PIM / DQM scope is also referred to as Multienterprise MDM.
A recent Gartner report states that: “Organizations that fail to understand their use cases, desired business outcomes and customer data governance requirements have difficulty choosing between CDPs and MDM solutions, because of overlapping capabilities.”
Indeed. This topic was examined here on the blog last year in the post CDP: Is that part of CRM or MDM?
Gartner compare the two breeds of solutions this way:
CDP platforms (via CRM applications) seems to hit from outside in without getting to the core of customer centrecity. MDM solutions are hitting the bullseye and some of the MDM solutions are moving inside out in the direction of extended MDM, where all customer data, not just customer master data, is encompassed under the same data governance umbrella.

Get the Gartner report Choose Between Customer Data Platforms and MDM Solutions for 360-Degree Customer Insights through Reltio here.
The Master Data Management (MDM) discipline is emerging. A certain trend is that MDM solutions will grow beyond handling traditional master data entities and encompass other kinds of data and more capabilities that can be used for other kinds of data as well.
 This include:
This include:
These themes were also covered in a webinar I presented with Semarchy last month. Watch the webinar The Intelligent Data Hub: MDM and Beyond.
