“I’d like to hear back from anyone who has implemented party master data in either a single, unified schema or separate, individual schemas (Vendor, Customer, etc.).
What were the pros and cons of your approach? Would you do it the same way if you had it to do again?”
This is a classic consideration at the heart of multi-domain MDM. As I see it, and what I advise my clients to do, is to have a common party (or business partner) structure for identification, names, addresses and contact data. This should be supported by data quality capabilities strongly build on external reference data (third party data). Besides this common structure, there should be specific structures for customer, vendor/supplier and other party roles.
This subject was also recently examined here on the blog in the post Multi-Side MDM.
What is your opinion and experience with this question? Please have your say either here on the blog or in the LinkedIn Multi-Domain MDM Group.
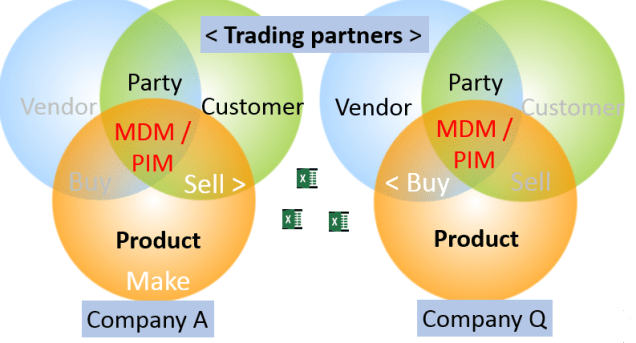
As reported in the post Gravitational Waves in the MDM World there is a tendency in the MDM (Master Data Management) market and in MDM programmes around to encompass both the party domain and the product domain.
The party domain is still often treated as two separate domains, being the vendor (or supplier) domain and the customer domain. However, there are good reasons for seeing the intersection of vendor master data and customer master data as party master data. These reasons are most obvious when we look at the B2B (business-to-business) part of our master data, because:
You will always find that many real world entities have a vendor role as well as a customer role to you
The basic master data has the same structure (identification, names, addresses and contact data
You need the same third party validation and enrichment capabilities for customer roles and vendor roles.
When we look at the product domain we also have a huge need to connect the buy side and the sell side of our business – and the make side for that matter where we have in-house production.
Multi-Domain MDM has a side effect, so to speak, about bringing the sell-side together with the buy- and make-side. PIM (Product Information Management), which we often see as the ancestor to product MDM, has the same challenge. Here we also need to bring the sell-side and and the buy-side together – on three frontiers:
Bringing the internal buy-side and sell-side together not at least when looking at product hierarchies
Bringing our buy-side in synchronization with our upstream vendors/suppliers sell-side when it comes to product data
Bringing our sell-side in synchronization with our downstream customers buy-side when it comes to product data
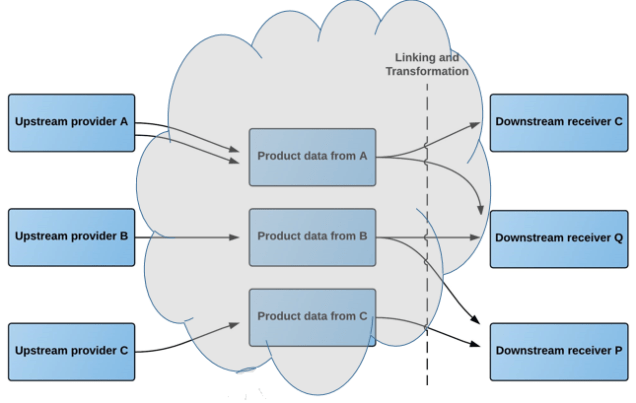
The Product Data Lake is a cloud service for sharing product data in the eco-systems of manufacturers, distributors, retailers and end users of product information.
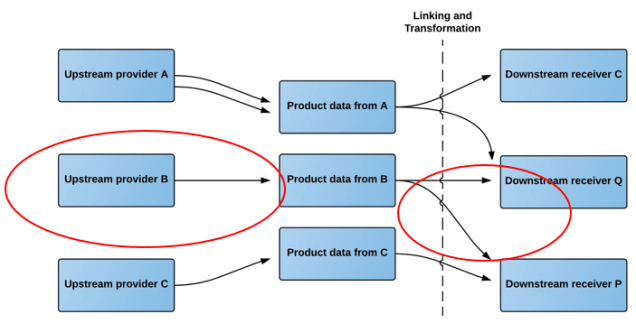
As an upstream provider of products data, being a manufacturer or upstream distributor, you have these requirements:
When you introduces new products to the market, you want to make the related product data and digital assets available to your downstream partners in a uniform way
When you win a new downstream partner you want the means to immediately and professionally provide product data and digital assets for the agreed range
When you add new products to an existing agreement with a downstream partner, you want to be able to provide product data and digital assets instantly and effortless
When you update your product data and related digital assets, you want a fast and seamless way of pushing it to your downstream partners
When you introduce a new product data attribute or digital asset type, you want a fast and seamless way of pushing it to your downstream partners.
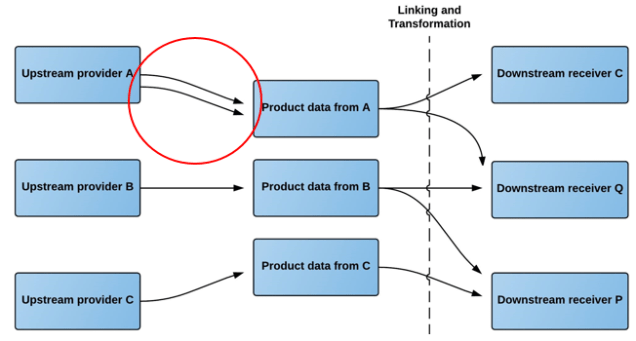
The Product Data Lake facilitates these requirements by letting you push your product data into the lake in your in-house structure that may or may not be fully or partly compliant to an international standard.
As an upstream provider, you may want to push product data and digital assets from several different internal sources.
The product data lake tackles this requirement by letting you operate several upload profiles.
As a downstream receiver of product data, being a downstream distributor, retailer or end user, you have these requirements:
When you engage with a new upstream partner you want the means to fast and seamless link and transform product data and digital assets for the agreed range from the upstream partner
When you add new products to an existing agreement with an upstream partner, you want to be able to link and transform product data and digital assets in a fast and seamless way
When your upstream partners updates their product data and related digital assets, you want to be able to receive the updated product data and digital assets instantly and effortless
When you introduce a new product data attribute or digital asset type, you want a fast and seamless way of pulling it from your upstream partners
If you have a backlog of product data and digital asset collection with your upstream partners, you want a fast and cost effective approach to backfill the gap.
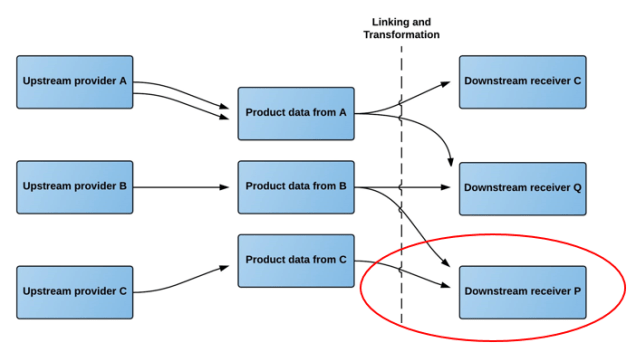
The Product Data Lake facilitates these requirements by letting you pull your product data from the lake in your in-house structure that may or may not be fully or partly compliant to an international standard.
In the Product Data Lake, you can take the role of being an upstream provider and a downstream receiver at the same time by being a midstream subscriber to the Product Data Lake. Thus, Product Data Lake covers the whole supply chain from manufacturing to retail and even the requirements of B2B (Business-to-Business) end users.
The Product Data Lake uses the data lake concept for big data by letting the transformation and linking of data between many structures be done when data are to be consumed for the first time. The goal is that the workload in this system has the resemblance of an iceberg where 10% of the ice is over water and 90 % is under water. In the Product Data Lake manually setting up the links and transformation rules should be 10 % of the duty and the rest being 90 % of the duty will be automated in the exchange zones between trading partners.
If you have ever visited some of the many castles around in Europe you may have noticed that there are many architectural similarities. You may also compare these basic structures of a castle with how we can imagine the data architecture related to Product Information Management (PIM).
In my vision of a product information castle there is a main building with five floors of product information. There is a basement for pricing information where we often will find the valuable things as the crown jewels and other treasures. The hierarchy tower combines the pricing information and the different levels of product information. Besides the main castle, we find the logistic stables.
Hierarchy, pricing and logistic is part of whole picture
What we do not see on this figure is the product lifecycle management wall around the castle area.
Now, let us get back to the main building and examine what is on each of the floors in the building.
Ground PIM level: Basic product data
On the ground level, we find the basic product data that typically is the minimum required for creating a product in any system of record. Here we find the primary product identification number or code that is the internal key to all other product data structures and transactions related to the product. Then there usually is a short product description. This description helps internal employees identifying a product and distinguishing that product from other products. If an upstream trading partner produces the product, we may find the identification of that supplier here. If the product is part of internal production, we may have a material type telling about if it is a raw material, semi-finished product, finished good or packing material.
Except for semi-finished products, we may find more things on the next floor.
PIM level 2: Product trade data
This level has product data related to trading the product. We may have a unique Global Trade Item Number (GTIN) that may be in the form of an International Article Number (EAN) or a Universal Product Code (UPC). Here we have commodity codes and a lot of other product data that supports buying, receiving, selling and delivering the product.
Most castles were not build in one go. Many castles started modestly in maybe just two floors and a tiny tower. In the same way, our product information management solutions for finished and trading goods usually are built on the top of an elder ERP solution holding the basic and trading data.
PIM Level 3: Basic product recognition data
On the third level, we find the two grand ballrooms of product information. These ballrooms were introduced when eCommerce started to grow up.
The extended product description is needed because the usual short product description used internally have no meaning to an outsider as told in the post Customer Friendly Product Master Data. Some good best practices for governing the extended product description is to have a common structure of how the description is written, not to use abbreviations and to have a strict vocabulary as reported in the post Toilet Seats and Data Quality.
Having a product image is pivotal if you want to sell something without showing the real product face-to-face with the customer or other end user. A missing product image is a sign of a broken business process for collecting product data as pondered in the post Image Coming Soon.
PIM Level 4: Self-service product data
On the fourth level, we have three main chambers: Product attributes, basic product relations and standard digital assets.This data are the foundation of customer self-service and should, unless you are the manufacturer, be collected from the manufacturer via supplier self-service.
Product attributes are also sometimes called product properties or product features. These are up to thousands of different data elements that describes a product. Some are very common for most products like height, length, weight and colour. Some are very specific to the product category. This challenge is actually the reason of being for dedicated Product Information Management (PIM) solutions as told in the post MDM Tools Revealed.
Basic product relations are the links between a product and other products like a product that have several different accessories that goes with the product or a product being a successor of another now decommissioned product.
Standard digital assets are documents like installation guides, line drawings and data sheets as examined in the post Digital Assets and Product MDM.
PIM Level 5: Competitive product data
On the upper fifth floor we find elements like on the fourth floor but usually these are elements that you won’t necessarily apply to all products but only to your top products where you want to stand out from the crowd and distance yourself from your competitors.
Special content are descriptions of and stories about the product above the hard features. Here you tell about why the product is better than other products and in which circumstances the product can to be used. A common aim with these descriptions is also Search Engine Optimization (SEO).
X-sell (cross-sell) and up-sell product relations applies to your particular mix of products and may be made subjective as for example to look at up-sell from a profit margin point of view. X-sell and up-sell relations may be defined from upstream by you or your upstream trading partners but also dripping down on the roof from the behaviour of your downstream trading partners / customers as manifested in the classic webshop message: “Those who bought product A also bought / looked at product B”.
Advanced digital assets are broader and more lively material than the hard fact line drawings and other documents. Increasingly newer digital media types as video are used for this purpose.
All in all the rooftop takes us to the upper side of the cloud.
Product Information Management (PIM) have over the recent years emerged as an important technology enabled discipline for every company taking part in a supply chain. These companies are manufacturers, distributor, retailers and large end users of tangible products requiring a drastic increased variety of product data to be used in ecommerce and other self-service based ways of doing business.
At the same time we have seen the raise of big data. Now, if you look at every single company, product data handled by PIM platforms perhaps does not count as big data. Sure, the variety is a huge challenge and the reason of being for PIM solutions as they handle this variety better than traditional Master Data Management (MDM) solutions and ERP solutions.
The variety is about very different requirements in data quality dimensions based on where a given product sits in the product hierarchy. Measuring completeness has to be done for the concrete levels in the hierarchy, as a given attribute may be mandatory for one product but absolutely ridiculous for another product. An example is voltage for a power tool versus for a hammer. With consistency, there may be attributes with common standards (for example product name) but many attributes will have specific standards for a given branch in the hierarchy.
Product information also encompasses digital assets, being PDF files with product sheets, line drawings and lots of other stuff, product images and an increasing amount of videos with installation instructions and other content. The volume is then already quite big.
A missing product image is a sign of a broken product data business process
Volume and velocity really comes into the game when we look at eco-systems of manufacturers, distributors and retailers. The total flow of product data can then be described with the common characteristics of big data: Volume, velocity and variety. Even if you look at it for a given company and their first degree of separation with trading partners, we are talking about big data where there is an overwhelming throughput of new product links between trading partners and updates to product information that are – or not least should have been – exchanged.
Within big data we have the concept of a data lake. A key success factor of a data lake solution is minimizing the use of spreadsheets. In the same way, we can use a data lake, sitting in the exchange zone between trading partners, for product information as elaborated further in the post Gravitational Collapse in the PIM Space.
The previous post on this blog was called Gravitational Waves in the MDM World. Building further on space science, I would like to use the concept of gravitational collapse, which is the process that happens when a star or other space object is born. In this process, a myriad of smaller objects are gathered into a more dense object.
PIM (Product Information Management) is part of the larger MDM (Master Data Management) world. PIM solutions offered today serves very well the requirements for organizing and supporting the handling of product information inside each organization.
However, there is an instability when observing two trading partners. Today, the most common mean to share product data is to exchange one or several spreadsheets with product identification and product attributes (sometimes also called properties or features). Such spreadsheets may also contain links to digital assets being product images, line drawing documents, installation videos and other rich media stuff.
As an upstream provider of product data, being a manufacturer or upstream distributor, you have these requirements:
When you introduces new products to the market, you want to make the related product data and digital assets available to your downstream partners in a uniform way
When you win a new downstream partner you want the means to immediately and professionally provide product data and digital assets for the agreed range
When you add new products to an existing agreement with a downstream partner, you want to be able to provide product data and digital assets instantly and effortless
When you update your product data and related digital assets, you want a fast and seamless way of pushing it to your downstream partners
When you introduce a new product data attribute or digital asset type, you want a fast and seamless way of pushing it to your downstream partners.
You may want to push product data and digital assets from several different internal sources.
As a downstream receiver of product data, being a downstream distributor, retailer or end user, you have these requirements:
When you engage with a new upstream partner you want the means to fast and seamless link and transform product data and digital assets for the agreed range from the upstream partner
When you add new products to an existing agreement with an upstream partner, you want to be able to link and transform product data and digital assets in a fast and seamless way
When your upstream partners updates their product data and related digital assets, you want to be able to receive the updated product data and digital assets instantly and effortless
When you choose to use a new product data attribute or digital asset type, you want a fast and seamless way of pulling it from your upstream partners
If you have a backlog of product data and digital asset collection with your upstream partners, you want a fast and cost effective approach to backfill the gap.
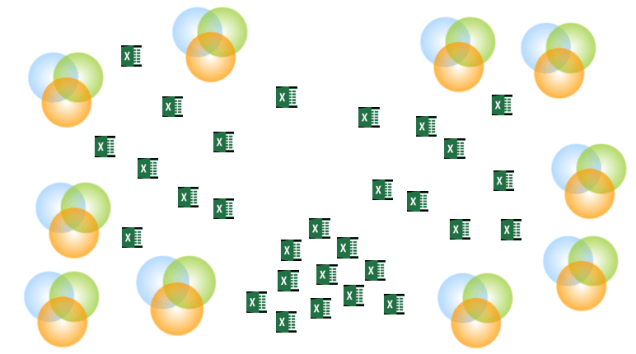
Fulfilling this with exchanging spreadsheets (and other peer-to-peer solutions) in the eco-system of trading partners is a chaotic mess.
If you look at it from upstream being a manufacturer or upstream distributor the challenge is that you probably have hundreds of downstream receivers of product information. Each one requires their form of spreadsheet or other interface. They may even ask you to use their specific supplier portal meaning hundreds of different learning exercises on your side.
As a downstream receiver of product information being a downstream distributor, retailer or end user you have the opposite challenges. You probably have hundreds of upstream providers. If you go for having your own supplier portal you need to teach each of your suppliers and you have the software license and others burdens.
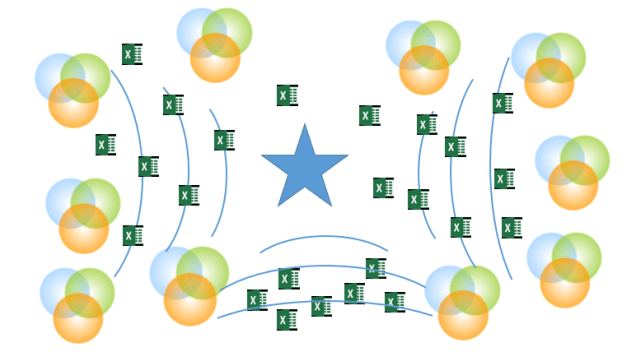
There is a need for a service that sits between the upstream and downstream trading partners. This service should help the upstream trading partners being manufactures and upstream distributors with sharing product data to many different downstream trading partners as well as it should eliminate or reduce the downstream trading partners need for implementing and maintaining supplier portals.
In the end such a service will collapse the doomed galaxy of spreadsheets into an agile process driven service for sharing product data – called the Product Data Lake.
One of the big news this week was the detection of gravitational waves. The big thing about this huge step in science is that we now will be able to see things in space, we could not see before. These are things we have plenty of clues about, but we cannot measure them because they do not emit electromagnetic radiation and the light from them is absorbed or reflected by cosmic bodies or dust before it reaches our telescopes.
We have kind of the same in the MDM (Master Data Management) world. We know that there is such a thing called multi-domain Master Data Management but our biggest telescope, the Gartner magic quadrants, only until now clearly identified customer Master Data Management and product Master Data Management as latest touched in the post The Perhaps Second Most Important MDM Quadrant 2015 is Out.
Indeed, many MDM programmes that actually does encompass all MDM domains do split the efforts into traditional domains as customer, vendor and product with separate teams observing their part of the sky. It takes a lot to advocate for that despite vendors belongs to the buy side and customers belongs to the sell side of the organization, there are strong ties between these objects. We can detect gravity in terms of that a vendor and a customer can be the same real world entity and vendors and customers have the same basic structure being a party.
Products do behave differently depending on the industry where your organization belongs. You may make products utilizing raw materials you buy and transform into finished products you sell or/and you may buy and sell the same physical product as a distributor, retailer or other value adding node in the supply chain. In order to handle the drastic increased demand for product data related to eCommerce, PIM (Product Information Management) has been known for long and many organizations everywhere in supply chains have already established PIM capabilities inside their organization with or without and inside or outside product Master Data Management.
What we still need to detect is a good system for connecting the PIM portion of sell sides upstream and buy sides downstream in supply chains. Right now we only see a blurred galaxy of spreadsheets as examined in the post Excellence vs Excel.
Today the 14th January in our times calendar used to be the first day in the new year when the Julian calendar was used before different countries at different times shifted to the Gregorian calendar.
Such shifts in what we generally refer to as reference data is a well-known pain in data management as exemplified in the post called The Country List. Within data warehouse management, we refer to this as Slowly Changing Dimensions.
Master Data Management (MDM) and Reference Data Management (RDM) are two closely related disciplines and often we may use the terms synonymously and indeed sometimes working with the same real world entity is MDM in one context but RDM in another context.
I have worked in industries, as public transit, where the calendar and related data must be treated as master data. But surely, in many other industries this will be an overkill. However, I have seen other entities treated as a simple List of Values (LoV) where it should be handled as master data or at least more complex reference data. Latest example is plants within a global company, where the highest ambition is proposed to be a mark for active or inactive, which hardly reflect the complexity in starting or buying a plant and closing or selling the same and the data management rules according to the changing states.
So happy 14th of January even if this is not New Year to you – but hey, at least it is my birthday.
In his blog post Dylan explains how data journeys are costly and risky. There are huge opportunities, not at least for data quality, in simplifying the sharing of data by breaking down the data boundaries.
The Berlin Wall. Fortunately it is not there anymore.
Data boundaries exists within organisations and between organisations. As the way of doing business today involves businesses working together, we see more and more data being sent between businesses. Unfortunately often using spreadsheets as told in post Excellence vs Excel.
We definitely need better ways to share data within organisations and between organisations. Furthermore, as Dylan points out, the data exchange needs to go in both directions. The ability to share data in an intelligent way is based on that data is identified and described by commonly shared reference and master data.
In my experience, the ability to collaborate between businesses by sharing reference and master data, and utilize available public sources, will be crucial in the quest for re-imagining data boundaries. This is indeed the future of data quality and The Future of Master Data Management.
I guess all people who works in data management curses Excel. Data kept in Excel is a pain – you know where – as it is hard to share, you never know if you have the latest version, nice informative colouring disappears when transforming, narrow columns turns into rubbish, different formatting usually makes it practically impossible to combine two sheets and heaps of other not so nice behaviours.
Even so, Excel is still the most used tool for many crucial data management purposes as for example reported in the post The True Leader in Product MDM.
Probably, the use of Excel as a mean to exchange data between organizations is the field where it will be most difficult to eliminate the dangerous use of Excel. The problem is that the alternative usually is far too rigid. The task of achieving consensus between many organizations on naming, formatting and all the other tedious stuff makes us turn to Excel.
When working with data quality within data management we may wrongly strive for perfection. We should rather strive for excellence, which is something better than the ordinary. In this case Excel is the ordinary. As Harriet Braiker said: “Striving for excellence motivates you; striving for perfection is demoralizing.”
In order to be excellent, though not perfect, in data sharing, we must develop solutions that are better than Excel without being too rigid. Right now, I am working on a solution for sharing product data being of that kind. The service is called the Product Data Lake.
 This is a classic consideration at the heart of multi-domain MDM. As I see it, and what I advise my clients to do, is to have a common party (or business partner) structure for identification, names, addresses and contact data. This should be supported by data quality capabilities strongly build on external reference data (third party data). Besides this common structure, there should be specific structures for customer, vendor/supplier and other party roles.
This is a classic consideration at the heart of multi-domain MDM. As I see it, and what I advise my clients to do, is to have a common party (or business partner) structure for identification, names, addresses and contact data. This should be supported by data quality capabilities strongly build on external reference data (third party data). Besides this common structure, there should be specific structures for customer, vendor/supplier and other party roles.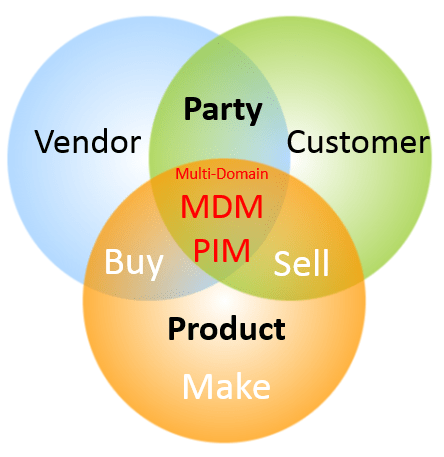
 As an upstream provider of products data, being a manufacturer or upstream distributor, you have these requirements:
As an upstream provider of products data, being a manufacturer or upstream distributor, you have these requirements: