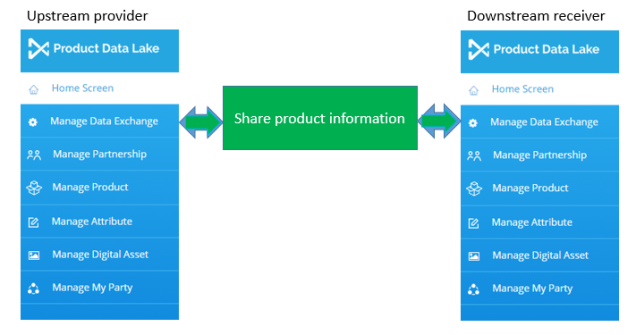
In our current work with the Product Data Lake cloud service, we are introducing a new way to connect product information that are stored at two different trading partners.
When doing that we deal with three kinds of product attributes:
- Product identification attributes
- Product classification attributes
- Product features
Product identification attributes
The most common used notion for a product identification attribute today is GTIN (Global Trade Item Number). This numbering system has developed from the UPC (Universal Product Code) being most popular in North America and the EAN (International Article Number formerly European Article Number).
Besides this generally used system, there are heaps of industry and geographical specific product identification systems.
In principle, every product in a given product data store, should have a unique value in a product identification attribute.
When identifying products in practice attributes as a model number at a given manufacturer and a product description are used too.
Product classification attributes
A product classification attribute says something about what kind of product we are talking about. Thus, a range of products in a given product data store will have the same value in a product classification attribute.
As with product identification, there is no common used standard. Some popular cross-industry classification standards are UNSPSC (United Nations Products and Service Code®) and eCl@ss, but many other standards exists too as told in the post The World of Reference Data.
Besides the variety of standards a further complexity is that these standards a published in versions over time and even if two trading partners use the same standard they may not use the same version and they may have used various versions depending on when the product was on-boarded.
Product features
A product feature says something about a specific characteristic of a given product. Examples are general characteristics as height, weight and colour and specific characteristics within a given product classification as voltage for a power tool.
Again, there are competing standards for how to define, name and identify a given feature.
 The Product Data Lake tagging approach
The Product Data Lake tagging approach
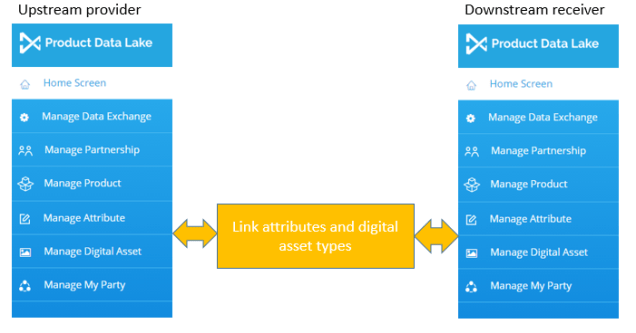
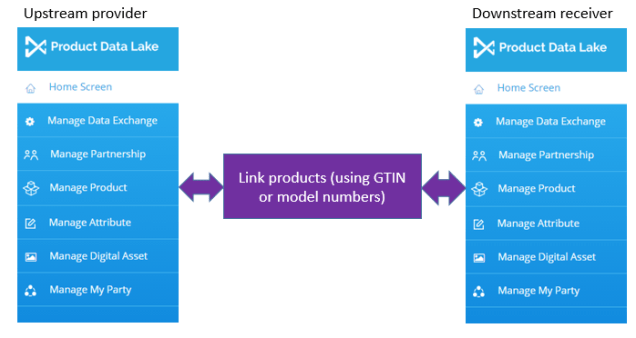
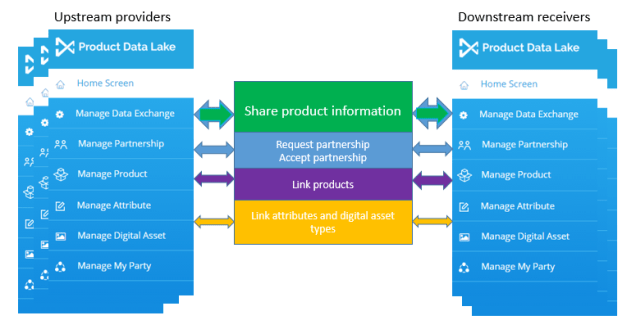
In the Product Data Lake we use a tagging system to typify product attributes. This tagging system helps with:
- Linking products stored at two trading partners
- Linking attributes used at two trading partners
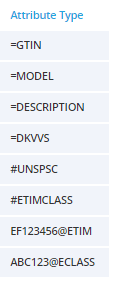
A product identification attribute can be tagged starting with = followed by the system and optionally the variant off the system used. Examples will be ‘=GTIN’ for a Global Trading Item Number and ‘=GTIN-EAN13’ for a 13 character EAN number. An industry geographical tag could be ‘=DKVVS’ for a Danish plumbing catalogue number (VVS nummer). ‘=MODEL’ is the tag of a model number and ‘=DESCRIPTION’ is the tag of the product description.
A product classification tag starts with a #. ‘#UNSPSC’ is for a United Nations Products and Service Code where ‘#UNSPSC-19’ indicates a given main version.
A product feature is tagged with the feature id, an @ and the feature (sometimes called property) standard. ‘EF123456@ETIM’ will be a specific feature in ETIM (an international standard for technical products). ‘ABC123@ECLASS’ is a reference to a property in eCl@ss.

 However, there are good reasons to consider using the blockchain approach when it comes to master data. A blockchain approach can be coined as centralized consensus, which can be seen as opposite to centralized registry. After the MDM discipline has been around for more than a decade, most practitioners agree that the single source of truth is not practically achievable within a given organization of a certain size. Moreover, in the age of business ecosystems, it will be even harder to achieve that between trading partners.
However, there are good reasons to consider using the blockchain approach when it comes to master data. A blockchain approach can be coined as centralized consensus, which can be seen as opposite to centralized registry. After the MDM discipline has been around for more than a decade, most practitioners agree that the single source of truth is not practically achievable within a given organization of a certain size. Moreover, in the age of business ecosystems, it will be even harder to achieve that between trading partners.



 Agility is a good thing, but of course, you have to put some control on top of it as reported in the post
Agility is a good thing, but of course, you have to put some control on top of it as reported in the post 

 But the market analysis and the trends observed is good stuff as well.
But the market analysis and the trends observed is good stuff as well.
