What is data quality anyway? This question has been touched many times on this blog.
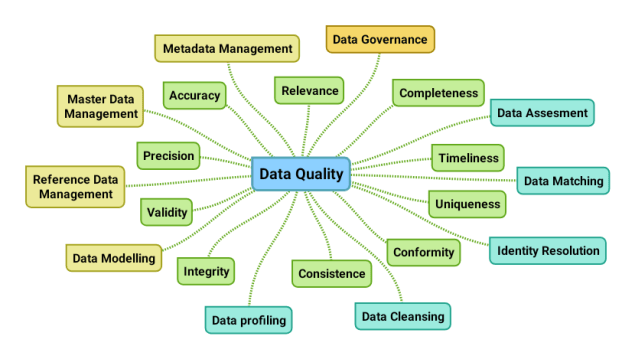
Data quality can be assessed using a range of data quality dimensions – the ones coloured green in the above mind map. These dimensions relate in different ways to various data domains as examined in the post Multi-Domain MDM and Data Quality Dimensions.
Data quality can be managed using a toolbox of sub disciplines – as the ones coloured turquoise in the above mind map. The reasons for data cleansing was discussed in the blog post Top 5 Reasons for Downstream Cleansing. Data profiling was visited in the post Data Quality Tools Revealed along with data matching. The relationship between data matching and identity resolution was recently described in the post Data Matching and Real-World Alignment.
The data quality discipline is closely related to – the yellow coloured – other disciplines as data modelling, Reference Data Management (RDM), Master Data Management (MDM), metadata management and – if not a sub discipline of – data governance as also shown in the post A Data Management Mind Map.

Very insightful post Henrik. I thought maybe you should add Automatability (ease of automation) to the data quality dimensions, but I guess it’s implied by Completeness and Timeliness. Perhaps Accessibility and Measurability are worth a place too, as unless business users can easily view and measure their data quality, it probably won’t be good enough and may not be improving.
Thanks for adding in Steve. I agree. If you cannot measure, you cannot improve. Automatability is new to me 🙂 Worth going for indeed.