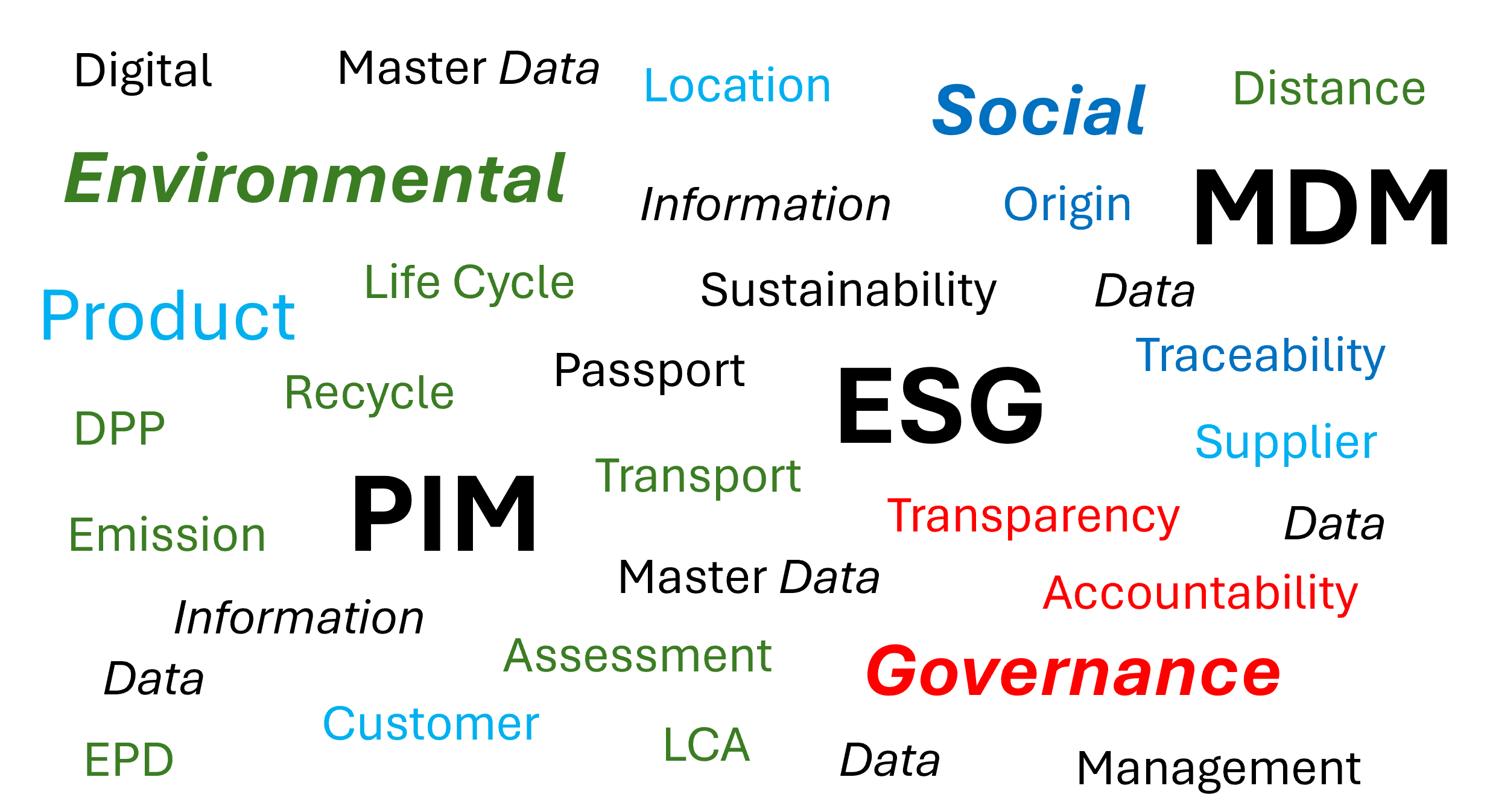
As touched on in the post Three Essential Trends in Data Management for 2024, the Environmental, Social and Governance (ESG) theme is high on the data management agenda in most companies. Lately I have worked intensively with the intersection of ESG and Master Data Management (MDM) / Product Information Management (PIM).
In this post I will go through some of the learnings from this.
Digital Product Passport
The European Union concept called the Digital Product Passport (DPP) is on its way, and it will affect several industries, including textile, apparel, and consumer electronics. The first product category that will need to comply with the regulation is batteries. Read more about that in the article from PSQR on the Important Takeaways from CIRPASS’ Final Event on DPP.
I have noticed that the MDM and PIM solution providers are composing a lot of their environmental sustainability support message around the DPP. This topic is indeed valid. However, we do not know many details about the upcoming DPP at this moment.
EPD, the Existing DPP Like Concept
There is currently a concept called Environmental Product Declaration (EPD) in force for building materials. It is currently not known to what degree the DPP concept will overlap the EPD at some point in the future. The EPD is governed by national bodies, but there are quite a lot of similarities between the requirements across countries. The EPD only covers environmental data whereas the DPP is expected to cover wider ESG aspects.
Despite the minor differences between DPP and EPD, there is already a lot to learn from the data management requirements for EPD in the preparation for the DPP when that concept materializes – so to speak.
Environmental Data Management
The typical touchpoint between the EPD and PIM today is that the published EPD document is a digital asset captured, stored, tagged, and propagated by the PIM solution along with other traditional digital assets as product sheets, installation guides, line drawings and more.
The data gathering for the EPD is a typical manual process today. However, as more countries are embracing the EPD, more buyers are looking for the EPD and the requirements for product granularity for the EPD are increasing, companies in the building material industry are looking for automation of the process.
The foundation for the EPD is a Life Cycle Assessment (LCA). That scope includes a lot of master data that reaches far beyond the finished product for which the EPD is created. This includes:
- The raw materials that go into the Bill of Materials.
- The ancillary materials that are consumed during production.
- The supplier’s location from where the above materials are shipped.
- The customer’s location to where the finished product is shipped.
- The end user location from where recycling products is shipped.
- The recycled product that goes back into the Bill of Materials.
All-in-all a clear case of Multi-Domain Master Data Management.
It is easy to imagine that the same will apply to products such as textile, apparel and electronics which are on the radar for the DPP.
Examples of Environmental Data
CO2 (or equivalent) emission is probably the most well known and quoted environmental data element as this has a global warming potential impact.
However, the EPD covers more than twenty other data elements relating to potential environmental impact including as for example:
- Ozone layer depletion potential – measured as CFC (or equivalent) emission.
- Natural resource (abiotic) depletion potential – measured as antimony (or equivalent) consumption.
- Use of fresh water – measured as H2O volume consumption.
Can I help You?
If you are in a company where environmental sustainability and data management is an emerging topic, I can help you set the scene for this. If you are at an MDM/PIM solution provider and need to enhance your offering around supporting environmental sustainability, I can help you set the scene for this. Book a short introduction meeting with me here.