I am aware that the title of this blog post is a bit geeky.
However, the terms are important in data management and your organisations ability to prosper in a continuously data driven world.
The term interenterprise was part of the previous post on this blog. The post was called What is Interenterprise Data Sharing? In a comment on LinkedIn analyst Simon Walker of Gartner explained interenterprise data sharing this way: “Interenterprise data sharing = Organizations are increasingly required to provide data to, and receive data from, external trading partners (customers, suppliers, business partners and others).”
Metadata is data about data. Handling metadata is an important facet of data management including in data governance, data quality management and Master Data Management (MDM). When it comes to the new trends in data management as big data and handling data in data lakes, the importance of metadata management will in my eyes become even more obvious.
In a current venture (Product Data Lake) we are working on building in metadata management for business ecosystems, meaning that trading partners can share product information either using the same metadata or linking their different metadata.
Using international, national and industry standards for product information will be the perfect solution within business ecosystem sharing of metadata and indeed this is the preferred option we support. However, there are many competing standards for product information and they come in developing versions, so having everyone on the same page at the same time is quite utopic.
Add to that everyone do not speak English – and even not the same variant of English. Metadata originates and should exist in the languages that is used in trading partnerships.
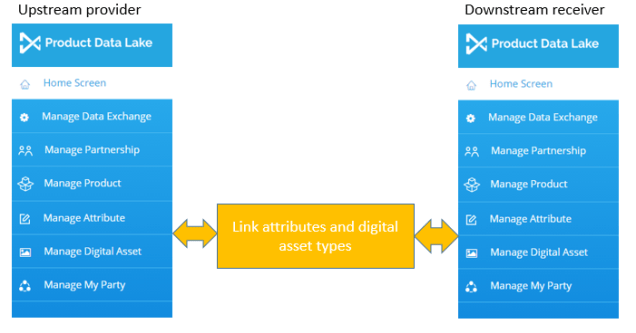
In Product Data Lake we have started out with these principles:
- Product attributes can be tagged with an attribute type telling about what standard (if any) in terms of product identification, product classification or product feature it adheres to. More about that in the post Connecting Product Information.
- Attribute short and long descriptions can be represented in different languages.
- Trading partners can link their product attributes and have visibility in the Product Data Lake of the standards and descriptions used in the different languages they exist.



 Handling the location as a separate unique entity can also be used in many industries as utility, telco, finance, transit and more.
Handling the location as a separate unique entity can also be used in many industries as utility, telco, finance, transit and more. Several other vendors as
Several other vendors as 


 This reminds me of when we talk about using robots to substitute human labor. Then we often think about a machine that looks like a human. But effective industrial robots do not look like humans. They a designed to do a specific process much more effective than a human and will therefore not look like a human. The same is true in digitalization. When we redesign business processes to be much more effective they should not include spreadsheets.
This reminds me of when we talk about using robots to substitute human labor. Then we often think about a machine that looks like a human. But effective industrial robots do not look like humans. They a designed to do a specific process much more effective than a human and will therefore not look like a human. The same is true in digitalization. When we redesign business processes to be much more effective they should not include spreadsheets.