The increased use of self-service based sales approaches as in ecommerce has put a lot of pressure on cross company supply chains. Besides handling the logistics and controlling pricing, you also have to take care of a huge amount of product data and digital assets describing the goods.
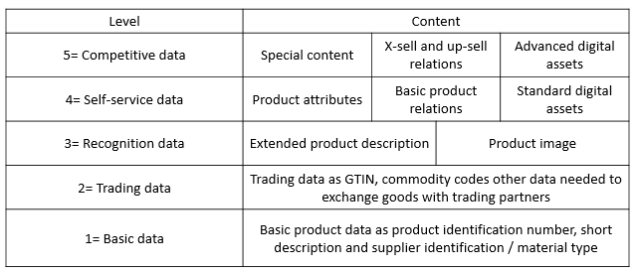
You may divide product information into these five levels:
Please learn more about the five levels of product information, including how hierarchies, pricing and logistics fits in, by visiting the product information castle.
Level 4 in this model is self-service product data being:
- Product attributes, also sometimes called product properties or product features. These are up to thousands of different data elements that describes a product. Some are very common for most products like height, length, weight and colour. Some are very specific to the product category. This challenge is actually the reason of being for dedicated Product Information Management (PIM) solutions.
- Basic product relations are the links between a product and other products like a product that have several different accessories that goes with the product or a product being a successor of another now decommissioned product.
- Standard digital assets are documents like installation guides, line drawings and data sheets.
These are the product data that helps the end customer comparing products and making an objective choice when buying a product for a specific purpose of use. These data are also helpful in answering the questions a buyer may have when making a purchase.
Every piece of data belonging to any level of product information may be forwarded through the cross company supply chain from the manufacturer to the end seller. Self-service product data are however the data that most obviously will do so.
In order to support end customer self-service when producing, distributing and selling goods you must establish a process driven service that automates the introduction of new products with extensive product data, the inclusion of new kinds of product data and updates to those data. You must be a digitalized member of your business ecosystem. The modern solution for that is the Product Data Lake.
![]()
 In a current role, I have worked a lot with sourcing product data from suppliers. One of our recurring examples is about one of our product categories being toilet seats. In that context, we have three different kind of suppliers:
In a current role, I have worked a lot with sourcing product data from suppliers. One of our recurring examples is about one of our product categories being toilet seats. In that context, we have three different kind of suppliers: