 Building materials is a very diverse product group. As a wholesaler or dealer, you will have to manage many different attributes and digital assets depending on which product classification we are talking about.
Building materials is a very diverse product group. As a wholesaler or dealer, you will have to manage many different attributes and digital assets depending on which product classification we are talking about.
Getting these data from a diverse crowd of suppliers is a hard job. You may have a spreadsheet for each product group where you require data from your suppliers, but this means a lot of follow up and work in putting the data into your system. You may have a supplier portal, but suppliers are probably reluctant to use it, because they cannot deal with hundreds of different supplier portals from you and all the other wholesalers and dealers possibly across many countries. In the same way that you are not happy about if you must fetch data from hundreds of different customer portals provided by manufacturers and other brand owners.
This also means that even if you can handle the logistics, you must limit your regular assortment of products and therefore often deal with special ad hoc products when they are needed to form a complete range of products asked for by your customers for a given building project. Handling of “specials” is a huge burden and the data gathering must usually be repeated if the product turns up again.
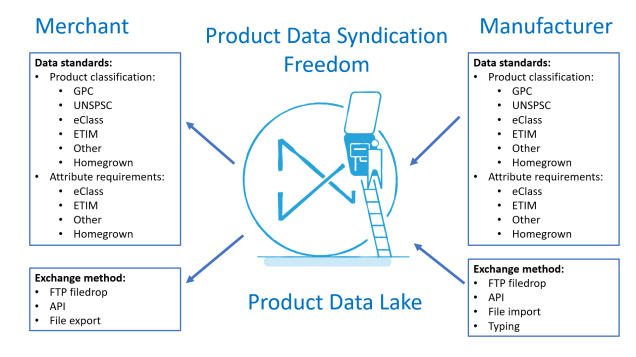
At Product Data Lake we have developed a solution to these challenges. It is a cloud service where your suppliers can provide product information in their way and you can pull the information in the way that fits your taxonomy, structure and format.
Learn about and follow the solution on our Product Data Pull LinkedIn page.
If you are interested, please ask for more information here:





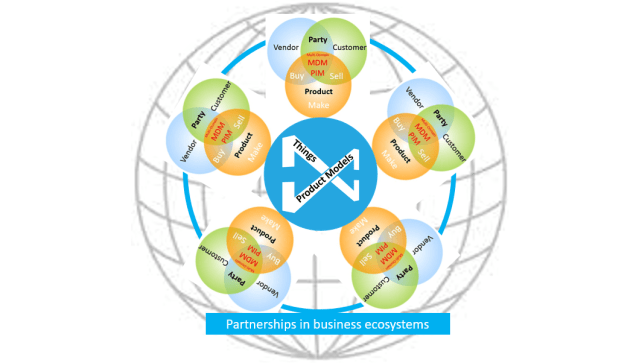
 The main enemy from a technology perspective is in my experience peer-to-peer system integration solutions. If you have chosen application X to support a business objective and application Y to support another business objective and you learn that there is an integration solution between X and Y available, this is very bad news. Because short term cost and timing considerations will make that option obvious. But in the long run it will cost you dearly if the master data involved are handled in other applications as well. Because then you will have blind spots all over the place where through duplicates will enter.
The main enemy from a technology perspective is in my experience peer-to-peer system integration solutions. If you have chosen application X to support a business objective and application Y to support another business objective and you learn that there is an integration solution between X and Y available, this is very bad news. Because short term cost and timing considerations will make that option obvious. But in the long run it will cost you dearly if the master data involved are handled in other applications as well. Because then you will have blind spots all over the place where through duplicates will enter.
