Today’s guest blogger is Sam Phipps, who is a supply chain blogger & marketing manager at Slimstock. As a supply chain blogger with a passion for inventory, Sam helps businesses to optimise their processes to boost availability, save cost and maximise customer satisfaction. In this article, Sam explores why ‘good’ master data is critical to supply chain success.
As the inventory expert, Tony Wild, once highlighted: “inventory is the physical consequence of missing data.”
But almost all businesses manage some form of master data. In fact, many organisations have an abundance of it. So, what’s the problem then?
Just because lots of data exists within a business, this does not mean that it is correct or complete. Furthermore, just because the data is in place, this doesn’t mean that master data is used effectively.
Every department within a business depends on good quality master data. However, in certain areas of business such as operations and supply chain management, poor data can quickly result in bad decisions that impact the entire organization.
Yet, around 50% of all businesses lack the core master data which are a pre-requisite for ‘good’ supply chain management. And even for the remaining 50%, master data is often seen as an area that could be improved upon.
Fundamental to supply chain success
In essence, supply chain master data includes all of the product and transactional information related to a given item. From determining logistics routes to setting up promotions, this information is used to make thousands of decisions.
But in the context of supply chain management, correct and reliable master data is an absolute must for satisfying customer demand. After all, the foundation of inventory and supply chain success revolves around two key questions:
- When should you place an order?
- How big should your order be?
To determine both of these points, we depend on several bits of key information. And, without this data, it would be impossible to know how much inventory you need to fulfil your customer’s demand.
To give a few examples, the supply chain master data typically encompasses the following areas:
- Specific details about the product in question (size, SKU number)
- Information about the supplier (lead times, MOQs)
- Details about the current inventory position (location, inventory level)
- Details about the customer
- Information around the past demand
- As well as many other key data elements
Driving long-term efficiency improvements
So far, we have only touched upon the basics: aligning supply with demand. However, this is just the start.
Through some fairly simple analysis techniques, master data can be used to explore new opportunities for optimisation.
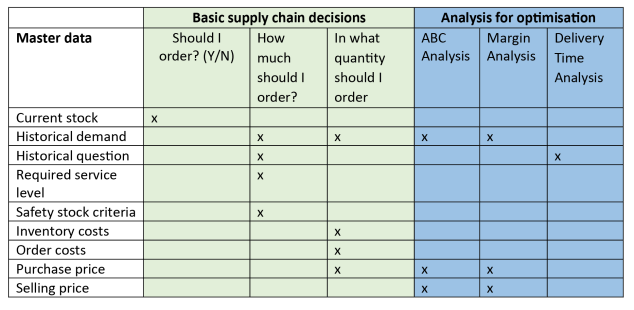
For example, the first area we can review is the ABC analysis. By focusing on how each item contributes to the overall business goals (whether than be profitability, sales turnover or something else), management can use this to determine which (and how many) products the company should prioritise.
We could also carry out a so-called Incremental Margin Analysis, which provides management with insight into which products contribute positively to the net margin.
Furthermore, we could explore the Delivery Time Deviation Distribution. This is an instrument that the supply chain team can use to gain insight into the performance of suppliers.
Each of these analyses requires slightly different master data elements. The table below provides an overview of what data is required.
Master data is everyone’s problem
No business can afford to overlook master data. But who should be the owner of the master data in your business? Should it be the IT, finance, operations, or even the management team?
This is a difficult question to ask. And many businesses don’t have a clear-cut answer. Although there is a technological process or system that the IT team need to support master data should be seen as a priority by everyone!
To read more about how you can optimise you supply chain master data, click here: https://www.slimstock.com/en/master-data/
