There are intersections between data modelling and data quality. In examining those we can use a data quality mind map published recently on this blog:
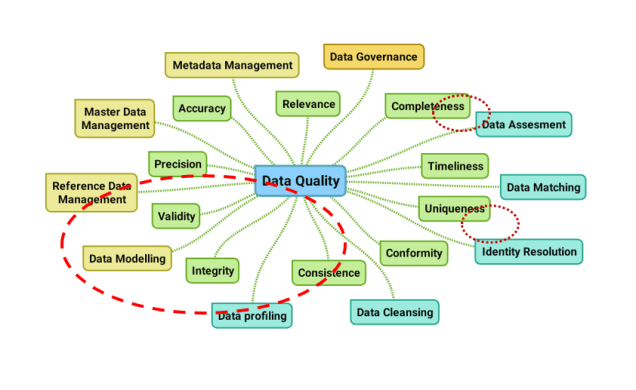
Data Modelling and Data Quality Dimensions:
Some data quality dimensions are closely related to data modelling and a given data model can impact these data quality dimensions. This is the case for:
- Data integrity, as the relationship rules in a traditional entity-relation based data model fosters the integrity of the data controlled in databases. The weak sides are, that sometimes these rules are too rigid to describe actual real-world entities and that the integrity across several databases is not covered. To discover the latter one, we may use data profiling methods.
- Data validity, as field definitions and relationship rules controls that only data that is considered valid can enter the database.
Some other data quality dimensions must be solved with either extended data models and/or alternative methodologies. This is the case for:
- Data completeness:
- A common scenario is that for example a data model born in the United States will set the state field within an address as mandatory and probably to accept only a value from a reference list of 50 states. This will not work in the rest of world. So, in order to not getting crap or not getting data at all, you will either need to extend the model or loosening the model and control completeness otherwise.
- With data about products the big pain is that different groups of products require different data elements. This can be solved with a very granular data model – with possible performance issues, or a very customized data model – with scalability and other issues as a result.
- Data uniqueness: A common scenario here is that names and addresses can be spelled in many ways despite that they reflect the same real-world entity. We can use identity resolution (and data matching) to detect this and then model how we link data records with real world duplicates together in a looser or tighter way.
Emerging technologies:
Some of the emerging technologies in the data storing realm are presenting new ways of solving the challenges we have with data quality and traditional entity-relationship based data models.
Graph databases and document databases allows for describing and operating data models better aligned with the real world. This topic was examined in the post Encompassing Relational, Document and Graph the Best Way.
In the Product Data Lake venture I am working with right now we are also aiming to solve the data integrity, data validity and data completeness issues with product data (or product information if you like) using these emerging technologies. This includes solving issues with geographical diversity and varying completeness requirements through a granular data model that is scalable, not only seen within a given company but also across a whole business ecosystem encompassing many enterprises belonging to the same (data) supply chain.
