As described in the post Small Data with Big Impact my guess is that we will see Master Data Management solutions as a core element in having data architectures that are able to make sustainable results from dealing with big data.
If we look at party master data a serious problem with many ERP and CRM systems around is that the data model for party master data aren’t good enough for dealing with the many different forms and differences in which the parties we hold data about are represented in big data sources which makes the linking between traditional systems of record and big data very hard.
Having a Master Data Management (MDM) solution with a comprehensive data model for party master data is essential here.
Some of the capabilities we need are:
Storing multiple occurrences of attributes
People and companies have many phone numbers, they have many eMail addresses and they have many social identities and you will for sure meet these different occurrences in big data sources. Relating these different occurrences to the same real world entity is essential as reported in the post 180 Degree Prospective Customer View isn’t Unusual.
An MDM hub with a corresponding data model is the place to manage that challenge in one place.
Exploiting rich external reference data
As told in the post Where the Streets have Two Names and emphasized in the comments to the post the real world has plenty of examples of the same thing having many names. And this real world will be reflected in big data sources.
Your MDM solution should embrace external reference data solving these issues.
Handling the time dimension
In the post A Place in Time the flaws of the usual customer table in ERP and CRM systems is examined. One common issue is handling when attributes changes. Change of address happens a lot. And this may be complicated by that we may operate several address types at the same time like visiting addresses, billing addresses and correspondence addresses. These different addresses will also pop up in big data sources. And the same goes for other attributes.
You must get that right in your MDM implementation.
![]()

Happy Thursday Henrik,
Of course, we would never disagree about the importance of MDM ;).
For connecting and enriching data together, what we see a lot, is the temptation to proceed with a series of manual or batch operations to refine and link data together, leaving the impression that once everything is set into a nicely integrated process, the problem is solved. It is indeed appealing and rewarding to build up these flows (and your boss gets impressed).
But it feels like coming back to the Excel time, way back when we would build these massive and macro full sheets, we just use bigger toys.
Don’t get me wrong, I love Big Data data crunching tools, but they are not suited for true MDM for the following reasons:
– They don’t offer roll-back in time features
– They don’t support model evolution and versioning
– Data lineage and audit trail is often limited
– They don’t provide any workflow where accountability and stewardship is involved
– Doing, undoing, correcting which is a common activity in MDM can’t be achieve in transparence and supervision.
When Sales, Compliance, Regulations, Audit are at stake, these MDM features are just a must.
Hi Henrik
Great points that you make.
Without the architecture that a Logical Data Model (LDM) provides, is not just difficult, it is impossible for any enterprise to effectively implement MDM. Merging physical data is just that – merging physical data! But what are the structures meant to be?
The LDM can also clearly show what structures are needed to support those elements such as contact details, addresses, etc. that change over time.
It is also refreshing to read a commentator in this field refer to the key Master Entity of ‘Party’ as opposed to the Phantom Entity of ‘Customer’ – a major blockage to MDM.
Regards
John
Good post.
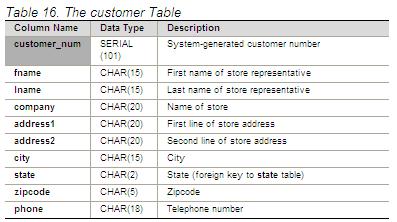
Using your example party table the issue for big data is the left hand side (column name) is fixed but what if it could change as much as the description column could in a regular system?
So we need an MDM model that accepts different named attributes per party and different parties could have different numbers of overall rows in their meta data table.
Quite a challenge.
Thanks a lot Gauthier, John and James for adding in. Indeed there a lot of aspects of MDM that tights into exploiting big data not at least when we comes to doing that in ongoing business processes.
This deserves to be re-shared. I’m running into this constantly. Clients do not understand the complexities and nuances required for MDM and are not supported with a traditional relational logical data model. In addition to the items you mentioned in your blog I would add a notation methodology to capture in the model the components for matching such as the equality (Deterministic) candidates as well as the fuzzy(probabilistic) matching candidates. from a logical perspective these are not just functions of a tool, they are in implicit an implied requirement for the model, especially if the model is going to contain some type of “lineage “concept. I believe capturing this type of metadata is critical in an MDM model methodology that would be understandable and actually implementable , independent of any specific vendor tool
Thanks for adding in Ira.
@Ira
Sorry, I have got to disagree. The only effective starting place for modelling the data structures required for effective MDM in any enterprise is with a logical data model (LDM). Also, there is no facet of these required structures that cannot be modelled using a LDM, including lineage concepts.
A Logical Data Model describes all of the metadata for all of an enterprise. The LDM is Metadata, i.e. Data describing the format an structure of data.
The LDM is the architectural wiring diagram for Master Data Management. It is also essential for removing the complexities that exist in the data structures of silo systems. Without this core diagram any MDM solution is simply guessing at what the correct MDM structures are.
Regards
John
I completely agree that a LDM is required and essential , however I specifically mentioned a ” traditional RELATIONAL logical data model”. As noted MASTER DATA MANAGEMENT AND DATA GOVERNANCE, 2/E by Alex Berson, Larry Dubov, ““In the MDM world, an MDM-Star schema is a natural representation of the concept of a master entity.” and ” For each master entity, define the entities that need to be resolved algorithmically due to the complexity. Examples of these will have high volumes of data and require advanced algorithms (probalistic matching). While I agree you can model the staging area traditionally and relationally, the actual MDM Model(Conceptual and Logical) will be living and supported either by a tool and or custom matching capabilities(Combination of deterministic and probabilistic) can not be properly represented with existing notations (Chen, Crowfoot etc..). This capability and functionality is generally the “heart and soul” of the MDM Model, and what separates it from a relational “Reference Model”.
@Ira
I think that it vital to separate the logical from the physical when discussing MDM structures.
Star models are one viable physical model for implementing a physical MDM solution to overcome the fragmentation caused by silo systems. However, the Logical Data Model is an essential tool required before you can design any viable physical solution, star or otherwise. It is also important to remember that the enterprise LDM is there to model the whole of the enterprise, not just the Master Entities.
In over 30 years of modelling enterprises of all sizes in a huge range of industries on both sides of the globe, I have not yet come across a viable business structure that could not be fully and effectively modelled using the ‘crowsfoot’ notation in a logical data model. In fact, if you are dealing with a data structure that cannot be modelled in this way, then you should probably not be implementing it, as it is unnecessarily complex and, very probably probably, unviable.
I am also confused as to why you say that any Master Entity management in any enterprise will involve high volumes of data. These entities are, by definition, stable and the transactions that create and update them will be low in volume.
It is the transactional data entities, such as Sale, Purchase, etc, which link Master Entities (e.g Party and Product), that will be high in volume and these are most effectively modelled at the logical level as intersection entities and most effectively implemented at the physical level as intersection tables.
Kind regards
John
John, Thank you, however I respectfully disagree
In this post Henrik is specifically referring to the problem of traditional modeling in an Master Data Management (Model) and the ability to process with ever changing big data sources populating multiple attributes. In today’s world I believe we need more then a tradition LDM or even Physical Model to communicate our design. Conceptually a master data model is the “real wold” business relationships, hence it’s similarity to a dimensional model, from the business perspective.
Again specifically from an MDM implementation perspective, for an LDM to have life and awaremant beyond initial implementation, it would have to be accompanied by set of supporting master data models that would properly define the relationships actually in place at a given time. Heinrich mentioned three see below:
Storing multiple occurrences of attributes
Exploiting rich external reference data
Handling the time dimension
Forgive me Henrik this is an excellent post and discussion but I would like to add the Challenge of modeling the “record linkage” or matching relationships to that list.
Only a very small group of folks in a typical engagement enterprise or even departmental really understand the LDM irrespective of how helpful it is from a development perspective.
I am not proposing that we do not create LDM, however I am agreeing and advocating with Henrik that we need to provide additional capabilities in order for users and other applications to understand the master data model relationships Heinrick that we provide additional capabilities and methods for explaining to users, and other applications seeking access to the MDM model it’s relationships.
Let’s take the problem of “record linkage” or the combination of equality matched attributes and a set of fuzzy match attributes. This is the centerpiece of populating the party model within a master data model. I understand from the LDM perspective that traditionally we’ve only been concerned with the target attribute and not the relationships that exist to populate it . However, the problem were facing today is in communicating to clients those relationships that are required to not only create but also to maintain master data model. You mentioned “merging data quote, I contend that and MDM implementation is the mother-in-law merging applications, and deserves a set of deliverables and models that will allow users to visually and quickly understand the relationship. Of course we can represent this scenario in the LDM as a many to many relationship, with little or no understanding “visually” of the context of the relationship
In terms of volume in this post, Heinrich is referring to big data, keep in mind that the MDM model will be accessed run against and used by applications that are processing a very high volume of data. It will be critical for them to understand specifically for individual attributes which are a quality based verses which are algorithmically(fuzzy) based.
Back to Henrik points I believe that he is spot on and that my take is that in a master data management implementation, there is a critical need to understand not only the LDM(the starting point), but also the master data model, and the “rules” visually, at least at a logical level. In my experience too many times we have created the logical model, and then began implementing the master data model, usually in a tool and do not have any of the artifacts, that I believe are required to properly communicate in an iterative development process.
Kind regards, Ira
Reblogged this on Ira Warren Whiteside's Blog and commented:
Interesting discussion on MDM , Logical Data Models and Big Data , hashing around approaches.