One problem with having English as the lingua franca on this planet is that English have a lot of different words meaning (almost) the same. One example is product, material, article, and item. This entity is the core entity within the master data domain we usually call the product domain.
I have experienced numerous occasions where these words are used to describe different perspectives across lifecycles or granularity in different ways within the same organization operating in manufacturing, distribution, retail, construction or comparable industry.
Product
The word product is part of the product domain in Master Data Management (MDM). It is also part of the adjacent discipline called Product Information Management (PIM). Also, it is part of the upcoming Digital Product Passport (DPP).
Furthermore, the word product is part of the term Universal Product Code (UPC) which is the North American version of the Global Trade Identification Number (GTIN).
We also have the word product as part of the term finished product.
If product is not the overarching term for material, article, and item it is often seen as either:
The sellable thing that comes out of a manufacturing process.
A higher level in a product hierarchy where there are varying articles/items on a lower level.
Material
In SAP, the predominant ERP application on this planet, the core product entity is called material.
We also have the word material as part of the term raw material.
Material is often seen as a thing that goes into a manufacturing or construction process.
Article
The word article is part of the term International Article Number previously known as European Article Number (EAN) which is the European version of the Global Trade Identification Number (GTIN).
An article is often seen as the level in a product hierarchy where you can assign a GTIN, meaning that the articles with the same GTIN have the same dimensions, color, other specifications, and packing.
This is equivalent to the term Stock Keeping Unit (SKU).
Item
Item is often used as an alternative or neutral term for product, material and/or article. Item is widely used as a column header for the sold products/materials/articles on an sales order and invoice or the requested products/materials/articles on a purchase order.
Proper use
As with so many other similar terms there is no generic proper use that your organization can stick to. There may be a trend or standard in your industry you can adhere to. Anyway, your data governance framework should be able to state the proper use within your organization as part of a business glossary.
Have you formed a business glossary or similar construct that defines how the words product/material/article/item/whatever (in your official language) should be used?
Data Matching is the discipline within data quality management where you deal with the probably most frequent data quality issue that you meet in almost every organization, which is duplicates in master data. This is duplicates in customer master data, duplicates in supplier master data, duplicates in combined / other business partner master data, duplicates in product master data and duplicates in other master data repositories.
A duplicate (or duplicate group) is where two (or more) records in a system or across multiple systems represent the same real-world entity.
Typically, you can use a tool to identify these duplicates. It can be as inexpensive as using Excel, it can be a module in a CRM or other application, it can be a capability in a Master Data Management (MDM) platform, or it can be a dedicated Data Quality Management (DQM) solution.
Over the years there have been developed numerous tools and embedded capabilities to tackle the data matching challenge. Some solutions focus on party (customer/supplier) master data and some solutions focus on product master data. Within party master data many solutions focus on person master data. Many solutions are optimized for a given geography or a few major geographies.
In my experience you can classify available tools / capabilities into the below 5 levels of efficiency:
The efficiency percentage here is an empirical measure of the percentage of actual duplicates the solution can identify automatically.
In more detail, the levels are:
1: Simple deterministic
Here you compare exact values between two duplicate candidate records or use simple transformed values as upper-case conversion or simple phonetic codes as for example soundex.
Don’t expect to catch every duplicate using this approach. If you have good, standardized master data 50 % is achievable. However, with a normal cleanliness, it will be lower.
Surprisingly many organizations still start here as a first step of reinventing the wheel in a Do-It-Yourself (DIY) approach.
2: Synonyms / standardization
In this more comprehensive approach you can replace, substitute, or remove values or words in values based on synonym lists. Examples are replacing person nicknames with guessed formal names, replacing common abbreviations in street names with a standardized term and removing legal forms in company names.
Enrichment / verification with external data can also be used, for example by standardizing addresses or classifying products.
3: Algorithms
Here you will use an algorithm as part of the comparison. Edit distance algorithms, as we know from autocorrection, are popular here. One frequently used one is the Levenshtein distance algorithm. But there are plenty out there to choose from each with their pros and cons.
Many data matching tools simply let you choose from using one of these algorithms in each scenario.
4: Combined traditional
If your DIY approach didn’t stop when encompassing more and more synonyms it will probably be here where you realize that further quest for raising efficiency includes combining several methodologies and doing dynamic combined algorithm utilization.
A minor selection of commercial data matching tools and embedded capabilities can do that for you so you avoid reinventing the wheel one more time.
This will yield high efficiency, but not perfection.
5: AI Enabled
Using Artificial Intelligence (AI) in data matching has been practiced for decades as told in the post The Art in Data Matching. With the general rise of AI in recent years there is renewed interest both at tool vendors and at users of data matching to industrialize this.
The results are still sparse out there. With limited training of models, it can be less efficient than traditional methodology. However, it can for sure also limit the gap between traditional efficiency and perfection.
More on Data Matching
There is of course much more to data matching than comparing duplicate candidates. Learn some more about The Art of Data Matching.
As touched on in the post Three Essential Trends in Data Management for 2024, the Environmental, Social and Governance (ESG) theme is high on the data management agenda in most companies. Lately I have worked intensively with the intersection of ESG and Master Data Management (MDM) / Product Information Management (PIM).
In this post I will go through some of the learnings from this.
Digital Product Passport
The European Union concept called the Digital Product Passport (DPP) is on its way, and it will affect several industries, including textile, apparel, and consumer electronics. The first product category that will need to comply with the regulation is batteries. Read more about that in the article from PSQR on the Important Takeaways from CIRPASS’ Final Event on DPP.
I have noticed that the MDM and PIM solution providers are composing a lot of their environmental sustainability support message around the DPP. This topic is indeed valid. However, we do not know many details about the upcoming DPP at this moment.
EPD, the Existing DPP Like Concept
There is currently a concept called Environmental Product Declaration (EPD) in force for building materials. It is currently not known to what degree the DPP concept will overlap the EPD at some point in the future. The EPD is governed by national bodies, but there are quite a lot of similarities between the requirements across countries. The EPD only covers environmental data whereas the DPP is expected to cover wider ESG aspects.
Despite the minor differences between DPP and EPD, there is already a lot to learn from the data management requirements for EPD in the preparation for the DPP when that concept materializes – so to speak.
Environmental Data Management
The typical touchpoint between the EPD and PIM today is that the published EPD document is a digital asset captured, stored, tagged, and propagated by the PIM solution along with other traditional digital assets as product sheets, installation guides, line drawings and more.
The data gathering for the EPD is a typical manual process today. However, as more countries are embracing the EPD, more buyers are looking for the EPD and the requirements for product granularity for the EPD are increasing, companies in the building material industry are looking for automation of the process.
The foundation for the EPD is a Life Cycle Assessment (LCA). That scope includes a lot of master data that reaches far beyond the finished product for which the EPD is created. This includes:
The raw materials that go into the Bill of Materials.
The ancillary materials that are consumed during production.
The supplier’s location from where the above materials are shipped.
The customer’s location to where the finished product is shipped.
The end user location from where recycling products is shipped.
The recycled product that goes back into the Bill of Materials.
All-in-all a clear case of Multi-Domain Master Data Management.
It is easy to imagine that the same will apply to products such as textile, apparel and electronics which are on the radar for the DPP.
Examples of Environmental Data
CO2 (or equivalent) emission is probably the most well known and quoted environmental data element as this has a global warming potential impact.
However, the EPD covers more than twenty other data elements relating to potential environmental impact including as for example:
Use of fresh water – measured as H2O volume consumption.
Can I help You?
If you are in a company where environmental sustainability and data management is an emerging topic, I can help you set the scene for this. If you are at an MDM/PIM solution provider and need to enhance your offering around supporting environmental sustainability, I can help you set the scene for this. Book a short introduction meeting with me here.
The impact of poor data quality issues in different industries such as healthcare, banking, and telecom cannot be overemphasized. It can lead to financial losses, customer churn, real-life impact on users, waste of resources, and conflicts within the data team. When a data quality issue arises, data managers, Chief Data Officers, and Data team leads are often the primary targets. Therefore, all data stakeholders must be as thorough and inquisitive as possible in their search for the right data quality tool that can solve their data problems. With numerous options in the market, it can be challenging to select the right tool that meets your unique data needs. In this article, four promising modern data quality tools are explored, each with its distinctive features, to help you make an informed decision.
Known for its user-friendly interface, Soda.io is a top pick for teams seeking an agile approach to data quality. It offers customizable checks and alerts, enabling businesses to maintain control over their data health. Soda.io excels in providing real-time insights, making it an excellent choice for dynamic data environments.
UNIQUE FEATURES
– User-friendly interface: Easy for teams to use and manage.
– Customizable checks and alerts: Tailor the tool to specific data health needs.
– Real-time insights: Immediate feedback on data quality issues.
Digna, with its AI-driven approach, stands out in how data quality issues are predicted, detected, and addressed. It not only flags data quality issues but also offers insights into their implications, helping businesses understand the impact on their operations. Digna’s unique selling points include its seamless integration, real-time monitoring, and the ability to provide reports on past data quality issues within three days – a process that typically takes months. It’s adaptable across various domains and ensures data privacy compliance while being scalable for any business size.
UNIQUE FEATURES
– AI-powered capabilities: Advanced predictive analysis and anomaly detection.
– Real-time monitoring: Immediate detection and notification of data quality issues.
– Automated Machine Learning: Efficiently corrects data irregularities.
– Scalability: Suitable for both startups and large enterprises.
– Flexible Installation: Cloud or On-prem installation, your choice.
– Automated Rule Validation: Say Goodbye to manually defining technical data quality rules. See the use case here
This tool offers a unique approach to data quality by focusing on data observability. Monte Carlo helps businesses monitor the health of their data pipelines, providing alerts for anomalies and breakdowns in data flow. It is particularly useful for companies with complex data systems, ensuring data reliability across the board.
UNIQUE FEATURES
– Focus on data observability: Monitors the health of data pipelines.
– Anomaly and breakdown alerts: Notifies about issues in data flow.
– Useful for complex data systems: Ensures reliability across all data.
Specializing in automatic data validation, Anomalo is ideal for businesses that deal with large volumes of data. It quickly identifies inconsistencies and errors, streamlining the data validation process. Anomalo’s machine learning algorithms adapt to your data, continually improving the detection of data quality issues.
UNIQUE FEATURES
– Automatic data validation: Ideal for handling large volumes of data.
– Machine learning algorithms: Adapt and improve issue detection over time.
– Quick identification of inconsistencies and errors: Streamlines the data validation process.
What You Should Know Before Choosing an Emerging Modern Data Quality Tool
Selecting the right data quality tool requires an understanding of your specific data challenges and goals. Consider how well it integrates with your existing infrastructure, the ease of setup and use, and the tool’s ability to scale as your data grows. Additionally, evaluate the tool’s ability to provide actionable insights and not just data alerts. The tool should be agile enough to adapt to various data types and formats while ensuring compliance with data privacy regulations.
In conclusion, whether you’re inclined towards the user-friendly approach of Soda.io, the observability focus of Monte Carlo, the automatic validation of Anomalo, or the AI-driven versatility of Digna, 2024 offers a range of top-tier data quality tools.
Digna in particular offers a comprehensive solution that stands out for its simplicity and effectiveness in data observability. Digna’s AI-driven approach not only predicts and detects data quality issues but also provides detailed alerts to users, ensuring that data problems are addressed promptly. With its ability to inspect a subset of customer data and provide rapid analysis, Digna saves costs and mitigates risks associated with data quality issues. Its seamless integration and real-time monitoring make it a user-friendly tool that fits effortlessly into any data infrastructure.
Make an informed choice today and steer your business toward data excellence with the right tool in hand.
Today’s guest blog post is from Marcin Chudeusz of DEXT.AI. a company specializing in creating Artificial Intelligence-powered Software for Data Platforms.
Have you ever experienced the frustration of missing crucial pieces in your data puzzle? The feeling of the weight of responsibility on your shoulders when data issues suddenly arise and the entire organization looks to you to save the day? It can be overwhelming, especially when the damage has already been done. In the constantly evolving world of data management, where data warehouses, data lakes, and data lakehouses form the backbone of organizational decision-making, maintaining high-quality data is crucial. Although the challenges of managing data quality in these environments are many, the solutions, while not always straightforward, are within reach.
Data warehouses, data lakes, and lakehouses each encounter their own unique data quality challenges. These challenges range from integrating data from various sources, ensuring consistency, and managing outdated or irrelevant data, to handling the massive volume and variety of unstructured data in data lakes, which makes standardizing, cleaning, and organizing data a daunting task.
Today, I would like to introduce you to Digna, your AI-powered guardian for data quality that’s about to revolutionize the game! Get ready for a journey into the world of modern data management, where every twist and turn holds the promise of seamless insights and transformative efficiency.
Digna: A New Dawn in Data Quality Management
Picture this: you’re at the helm of a data-driven organization, where every byte of data can pivot your business strategy, fuel your growth, and steer you away from potential pitfalls. Now, imagine a tool that understands your data and respects its complexity and nuances. That’s Digna for you – your AI-powered guardian for data quality.
Goodbye to Manually Defining Technical Data Quality Rules
Gone are the days when defining technical data quality rules was a laborious, manual process. You can forget the hassle of manually setting thresholds for data quality metrics. Digna’s AI algorithm does it for you, defining acceptable ranges and adapting as your data evolves. Digna’s AI learns your data, understands it, and sets the rules for you. It’s like having a data scientist in your pocket, always working, always analyzing.
Figure 1: Learn how Digna’s AI algorithm defines acceptable ranges for data quality metrics like missing values. Here, the ideal count of missing values should be between 242 and 483, and how do you manually define technical rules for that?
Seamless Integration and Real-time Monitoring
Imagine logging into your data quality tool and being greeted with a comprehensive overview of your week’s data quality. Instant insights, anomalies flagged, and trends highlighted – all at your fingertips. Digna doesn’t just flag issues; it helps you understand them. Drill down into specific days, examine anomalies, and understand the impact on your datasets.
Whether you’re dealing with data warehouses, data lakes, or lakehouses, Digna slips in like a missing puzzle piece. It connects effortlessly to your preferred database, offering a suite of features that make data quality management a breeze. Digna’s integration with your current data infrastructure is seamless. Choose your data tables, set up data retrieval, and you’re good to go.
Figure 2: Connect seamlessly to your preferred database. Select specific tables from your database for detailed analysis by Digna.
Navigate Through Time and Visualize Data Discrepancies
With Digna, the journey through your data’s past is as simple as a click. Understand how your data has evolved, identify patterns, and make informed decisions with ease. Digna’s charts are not just visually appealing; they’re insightful. They show you exactly where your data deviated from expectations, helping you pinpoint issues accurately.
With Digna, every column in your data table gets attention. Switch between columns, unravel anomalies, and gain a holistic view of your data’s health. It doesn’t just monitor data values; it keeps an eye on the number of records, offering comprehensive analysis and deep insights with minimal configuration. Digna’s user-friendly interface ensures that you’re not bogged down by complex setups.
Figure 3: Observe how Digna tracks not just data values but also the number of records for comprehensive analysis. Transition seamlessly to Dataset Checks and witness Digna’s learning capabilities in recognizing patterns.
Real-time Personalized Alert Preferences
Digna’s alerts are intuitive and immediate, ensuring you’re always in the loop. These alerts are easy to understand and come in different colors to indicate the quality of the data. You can customize your alert preferences to match your needs, ensuring that you never miss important updates. With this simple yet effective system, you can quickly assess the health of your data and stay ahead of any potential issues. This way, you can avoid real-life impacts of data challenges.
Whether you prefer inspecting your data directly from the dashboard or integrating it into your workflow, I invite you to commence your data quality journey. It’s more than an inspection; it’s an exploration—an adventure into the heart of your data with a suite of features that considers your data privacy, security, scalability, and flexibility.
Automated Machine Learning
Digna leverages advanced machine learning algorithms to automatically identify and correct anomalies, trends, and patterns in data. This level of automation means that Digna can efficiently process large volumes of data without human intervention, erasing errors and increasing the speed of data analysis.
The system’s ability to detect subtle and complex patterns goes beyond traditional data analysis methods. It can uncover insights that would typically be missed, thus providing a more comprehensive understanding of the data.
This feature is particularly useful for organizations dealing with dynamic and evolving data sets, where new trends and patterns can emerge rapidly.
Domain Agnostic
Digna’s domain-agnostic approach means it is versatile and adaptable across various industries, such as finance, healthcare, and telcos. This versatility is essential for organizations that operate in multiple domains or those that deal with diverse data types.
The platform is designed to understand and integrate the unique characteristics and nuances of different industry data, ensuring that the analysis is relevant and accurate for each specific domain.
This adaptability is crucial for maintaining accuracy and relevance in data analysis, especially in industries with unique data structures or regulatory requirements.
Data Privacy
In today’s world, where data privacy is paramount, Digna places a strong emphasis on ensuring that data quality initiatives are compliant with the latest data protection regulations.
The platform uses state-of-the-art security measures to safeguard sensitive information, ensuring that data is handled responsibly and ethically.
Digna’s commitment to data privacy means that organizations can trust the platform to manage their data without compromising on compliance or risking data breaches.
Built to Scale
Digna is designed to be scalable, accommodating the evolving needs of businesses ranging from startups to large enterprises. This scalability ensures that as a company grows and its data infrastructure becomes more complex, Digna can continue to provide effective data quality management.
The platform’s ability to scale helps organizations maintain sustainable and reliable data practices throughout their growth, avoiding the need for frequent system changes or upgrades.
Scalability is crucial for long-term data management strategies, especially for organizations that anticipate rapid growth or significant changes in their data needs.
Real-time Radar
With Digna’s real-time monitoring capabilities, data issues are identified and addressed immediately. This prompt response prevents minor issues from escalating into major problems, thus maintaining the integrity of the decision-making process.
Real-time monitoring is particularly beneficial in fast-paced environments where data-driven decisions need to be made quickly and accurately.
This feature ensures that organizations always have the most current and accurate data at their disposal, enabling them to make informed decisions swiftly.
Choose Your Installation
Digna offers flexible deployment options, allowing organizations to choose between cloud-based or on-premises installations. This flexibility is key for organizations with specific needs or constraints related to data security and IT infrastructure.
Cloud deployment can offer benefits like reduced IT overhead, scalability, and accessibility, while on-premises installation can provide enhanced control and security for sensitive data.
This choice enables organizations to align their data quality initiatives with their broader IT and security strategies, ensuring a seamless integration into their existing systems.
Conclusion
Addressing data quality challenges in data warehouses, lakes, and lakehouses requires a multifaceted approach. It involves the integration of cutting-edge technology like AI-powered tools, robust data governance, regular audits, and a culture that values data quality.
Digna is not just a solution; it’s a revolution in data quality management. It’s an intelligent, intuitive, and indispensable tool that turns data challenges into opportunities.
I’m not just proud of what we’ve created at DEXT.AI; I’m most excited about the potential it holds for businesses worldwide. Join us on this journey, schedule a call with us, and let Digna transform your data into a reliable asset that drives growth and efficiency.
Cheers to modern data quality at scale with Digna!
This article was written by Marcin Chudeusz, CEO and Co-Founder of DEXT.AI. a company specializing in creating Artificial Intelligence-powered Software for Data Platforms. Our first product, Digna offers cutting-edge solutions through the power of AI to modern data quality issues.
Contact me to discover how Digna can revolutionize your approach to data quality and kickstart your journey to data excellence.
On the edge of the New Year, it is time to guess what will be the hot topics in data management next year. My top three candidates are:
Continued Enablement of Augmented Data Management
Embracing Data Ecosystems
Data Management and ESG
Continued Enablement of Augmented Data Management
The term augmented data management is still a hyped topic in the data management world. “Augmented” is here used to describe an extension of the capabilities that is now available for doing data management with these characteristics:
Inclusion of Machine Learning (ML) and Artificial Intelligence (AI) methodology and technology to handle data management challenges that until now have been poorly solved using traditional methodology and technology.
Encompassing graph approaches and technology to scale and widen data management coverage towards data that is less structured and have more variation than data that until now has been formally managed as an asset.
Aiming at automating data management tasks that until now have been solved in manual ways or simply not been solved at all due to the size and complexity of the work involved.
It is worth noticing that the Artificial Intelligence theme lately has been dominated by generative AI and namely ChatGPT. However, for data management generative AI will in my eyes not be the most frequently used AI flavor. Learn more about data management and AI in the post Three Augmented Data Management Flavors.
The infrastructure that connects ecosystem participants and help organizations transform from local and linear ways of doing business toward virtual and exponential operations.
A single source of truth for ecosystem participants that becomes a single source of truth across business partner ecosystems by providing all ecosystem participants with access to the same data.
Business model and process transformation across industries to support agile reconfiguration of business models and processes through information exchange inside and between ecosystems.
In short, your organization cannot grow faster than your competitors by hiding all data behind your firewall. You must share relevant data within your business ecosystem in an effective manner.
Data Management and ESG
ESG stands for Environmental, Social and Governance. This is often called sustainability. In a business context, sustainability is about how your products and services contribute to sustainable development.
When working as a data management consultant I have seen more and more companies having ESG on top of the agenda and therefore embarking on programs to infuse ESG concepts into data management. If you can tie a proposed data management effort to ESG, you have a good chance of getting that effort approved and funded.
Capturing ESG data is very much about sharing data with your business partners. This includes getting new product data elements from upstream trading partners and providing such data to downstream trading partners. These new data elements are often not covered through traditional ways of exchanging product data. Getting the traditional product information through data supply chains is already challenged so adding the new ESG dimension is a daunting task for many organizations.
Therefore, we are ramping up to also cover ESG data in the collaborative product data syndication service I am involved in and is called Product Data Lake.
Today’s guest blog post is from Marcin Chudeusz of DEXT.AI. a company specializing in creating Artificial Intelligence-powered Software for Data Platforms.
Data quality isn’t just a technical issue; it’s a journey full of challenges that can affect not only the operational efficiency of an organization but also its morale. As an experienced data warehouse consultant, my journey through the data landscape has been marked with groundbreaking achievements and formidable challenges. The latter, particularly in the realm of data quality in some of the most data-intensive industries: banks, and telcos, have given me profound insights into the intricacies of data management. My story isn’t unique in data analytics, but it highlights the evolution necessary for businesses to thrive in the modern data environment.
Let me share with you a part of my story that has shaped my perspective on the importance of robust data quality solutions.
The Daily Battles with Data Quality
In the intricate data environments of banks and telcos, where I spent much of my professional life, data quality issues were not just frequent; they were the norm.
The Never-Ending Cycle of Reloads
Each morning would start with the hope that our overnight data loads had gone smoothly, only to find that yet again, data discrepancies necessitated numerous reloads, consuming precious time and resources. Reloads were not just a technical nuisance; they were symptomatic of deeper data quality issues that needed immediate attention.
Delayed Reports and Dwindling Trust in Data
Nothing diminishes trust in a data team like the infamous phrase “The report will be delayed due to data quality issues.” Stakeholders don’t necessarily understand the intricacies of what goes wrong—they just see repeated failures. With every delay, the IT team’s credibility took a hit.
Team Conflicts: Whose Mistake Is It Anyway?
Data issues often sparked conflicts within teams. The blame game became a routine. Was it the fault of the data engineers, the analysts, or an external data source? This endless search for a scapegoat created a toxic atmosphere that hampered productivity and satisfaction.
Data quality issues aren’t just a technical problem; they’re a people problem. The complexity of these problems meant long hours, tedious work, and a general sense of frustration pervading the team. The frustration and difficulty in resolving these issues created a bad atmosphere and made the job thankless and annoying.
Decisions Built on Quicksand
Imagine making decisions that could influence millions in revenue based on faulty reports. We found ourselves in this precarious position more often than I care to admit. Discovering data issues late meant that critical business decisions were sometimes made on unstable foundations.
High Turnover: A Symptom of Data Discontent
The relentless cycle of addressing data quality issues began to wear down even the most dedicated team members. The job was not satisfying, leading to high turnover rates. It wasn’t just about losing employees; it was about losing institutional knowledge, which often exacerbated the very issues we were trying to solve.
The Domino Effect of Data Inaccuracies
Metrics are the lifeblood of decision-making, and in the banking and telecom sectors, year-to-month and year-to-date metrics are crucial. A single day’s worth of bad data could trigger a domino effect, necessitating recalculations that spanned back days, sometimes weeks. This was not just time-consuming—it was a drain on resources amongst other consequences of poor data quality.
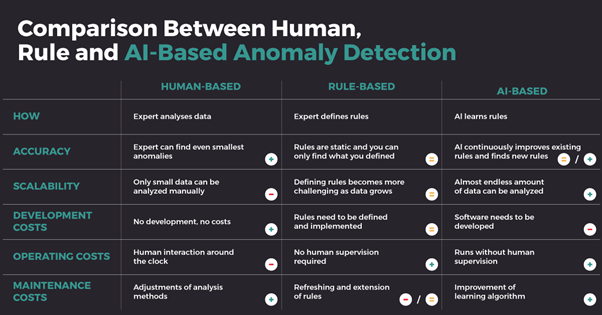
The Manual Approach to Data Quality Validation Rules
As an experienced data warehouse consultant, I initially tried to address these issues through the manual definition of validation rules. We believed that creating a comprehensive set of rules to validate data at every stage of the data pipeline would be the solution. However, this approach proved to be unsustainable and ineffective in the long run.
The problem with manual rule definition was its inherent inflexibility and inability to adapt to the constantly evolving data landscape. It was a static solution in a dynamic world. As new data sources, data transformations, and data requirements emerged, our manual rules were always a step behind, and keeping the rules up-to-date and relevant became an arduous and never-ending task.
Moreover, as the volume of data grew, manually defined rules could not keep pace with the sheer amount of data being processed. This often resulted in false positives and negatives, requiring extensive human intervention to sort out the issues. The cost and time involved in maintaining and refining these rules soon became untenable.
Comparison between Human, Rule, and AI-based Anomaly Detection
Embracing Automation: The Path Forward
This realization was the catalyst for the foundation of dext.ai. Danijel (Co-founder at Dext.ai) and I combined our AI and IT Know-How to create AI-powered software for Data Warehouses. This led to our first product Digna, we needed intelligent, automated systems that could adapt, learn, and preemptively address data quality issues before they escalated. By employing machine learning and automation, we could move from reactive to proactive, from guesswork to precision.
Automated data quality tools don’t just catch errors—they anticipate them. They adapt to the ever-changing data landscape, ensuring that the data warehouse is not just a repository of information, but a dependable asset for the organization.
Today, we’re pioneering the automation of data quality to help businesses navigate the data quality landscape with confidence. We’re not just solving technical issues; we’re transforming organizational cultures. No more blame games, no more relentless cycles of reloads—just clean, reliable data that businesses can trust.
In the end, navigating the data quality landscape isn’t just about overcoming technical challenges; it’s about setting the foundation for a more insightful, efficient, and harmonious future. This is the lesson my journey has taught me, and it is the mission that drives us forward at dext.ai.
This article was written by Marcin Chudeusz, CEO and Co-Founder of DEXT.AI. a company specializing in creating Artificial Intelligence-powered Software for Data Platforms. Our first product, Digna offers cutting-edge solutions through the power of AI to modern data quality issues.
Contact us to discover how Digna can revolutionize your approach to data quality and kickstart your journey to data excellence.
Earlier this year Gartner published a report with the title Top Trends in Data and Analytics, 2023. The report is currently available on the Parsionate site here.
The report names three opportunities within this theme:
Think Like a Business,
From Platforms to Ecosystems and
Don’t Forget the Humans
While thinking like a business and don’t forget the humans are universal opportunities that have always been here and will always be, the move from platforms to ecosystems is a current opportunity worth a closer look.
Here data sharing, according to Gartner, is essential. Some recommended actions are to
Consider adopting data fabric design to enable a single architecture for data sharing across heterogeneous internal and external data sources.
Brand data reusability and resharing as a positive for business value, including ESG (Environmental, Social and Governance) efforts.
Data Fabric is the Gartner buzzword that resembles the competing non-Gartner buzzword Data Mesh. According to Gartner, organizations use data fabrics to capture data assets, infer new relationships in datasets and automate actions on data.
Data sharing can be internal and external.
In my mind there are two pillars in internal data sharing:
MDM (Master Data Management) with the aim of sharing harmonized core data assets as for example business partner records and product records across multiple lines of business, geographies, and organizational disciplines.
Knowledge graph approaches where MDM is supplemented by modern capabilities in detecting many more relationships (and entities) than before as explained in the post MDM and Knowledge Graph.
In external data sharing we see solutions for:
Sharing the burden of collecting business partner records like CDQ.
External data sharing is on the rise, however at a much slower pace than I had anticipated. The main obstacle seems to be that the internal data sharing is still not mature in many organizations and that external data sharing require interaction between at least two data mature organizations.
Most Master Data Management implementations revolve around the business partner (customer/supplier) domain and/or the product domain. But there is a growing appetite for also including the finance domain in MDM implementations. Note that the finance domain here is about finance related master data that every organization has and not the specific master data challenges that organizations in the financial service sector have. The latter topic was covered on this blog in a post called “Master Data Management in Financial Services”.
In this post I will examine some high-level considerations for implementing an MDM platform that (also) covers finance master data.
Finance master data can roughly be divided into these three main object types:
Chart of accounts
Profit and cost centers
Accounts receivable and accounts payable
Chart of Accounts
The master data challenge for the chart of accounts is mainly about handling multiple charts of accounts as it appears in enterprises operating in multiple countries, with multiple lines of business and/or having grown through mergers and acquisitions.
For that reason, solutions like Hyperion have been used for decades to consolidate finance performance data for multiple charts of accounts possibly held in multiple different applications.
Where MDM platforms may improve the data management here is first and foremost related to the processes that take place when new accounts are added, or accounts are changed. Here the MDM platform capabilities within workflow management, permission rights and approval can be utilized.
Profit and Cost Centers
The master data challenge for profit and cost centers relates to an extended business partner concept in master data management where external parties as customers and suppliers/vendors are handled together with internal parties as profit and cost centers who are internal business units.
Here silo thinking still rules in my experience. We still have a long way to go within data literacy in order to consolidate financial perspectives with HR perspectives, sales perspectives and procurement perspectives within the organization.
Accounts Receivable and Accounts Payable
The accounts receivable data has an overlap and usually share master data with customer master data that are mastered from a sales and service perspective and accounts payable data has an overlap and usually share master data with supplier/vendor master data that are mastered from a procurement perspective.
But there are differences in the selection of parties covered as touched on in the post “Direct Customers and Indirect Customers”. There are also differences in the time span of when the overlapping parties are handled. Finally, the ownership of overlapping attributes is always a hard nut to crack.
A classic source of mess in this area is when you have to pay money to a customer and when you get money from a supplier. This most often leads to creation of duplicate business partner records.
MDM Platforms and Finance Master Data
Many large enterprises use SAP as their ERP platform and the place of handling finance master data. Therefore, the SAP MDG-F offer for MDM is a likely candidate for an MDM platform here with the considerations explored in the post “SAP and Master Data Management”.
However, if the MDM capabilities in general are better handled with a non-SAP MDM platform as examined in the above-mentioned post, or the ERP platform is not (only) SAP, then other MDM platforms can be used for finance master data as well.
Informatica and Stibo STEP are two examples that I have worked with. My experience so far is though that compared to the business partner domain and the product domain these platforms at the current stage do not have much to offer for the finance domain in terms of capabilities and methodology.
SAP is the predominant ERP solution for large companies, and it seems to continue that way as nearly all these organizations are currently on the path of updating and migrating from the old SAP version to the new SAP S/4 HANA solution.
During this process there is a welcomed focus on master data and the surrounding data governance. For the technical foundation for that we see 4 main scenarios:
Handling the master data management within the SAP ERP solution
Adding a plugin for master data management
Adding the SAP MDG offering to the SAP application stack
Adding a non-SAP MDM offering to the IT landscape
Let’s have a brief look into these alternative options:
MDM within SAP ERP
In this option you govern the master data as it is represented in the SAP ERP data model.
When going from the old R/3 solution to the new S/4 solution there are some improvements in the data model. This includes:
All business partners are in the same structure instead of having separate structures for customers and suppliers/vendors as in the old solutions.
The structure for material master objects is also consolidated.
For the finance domain accounts now also covers the old cost elements.
The advantage of doing MDM within SAP ERP is avoiding the cost of ownership of additional software. The governance though becomes quite manual typically with heavy use of supplementary spreadsheets.
Plugins
There are various forms of third-party plugins that help with data governance and ensuring the data quality for master data within SAP ERP. One of those I have worked with is it.master data simplified (it.mds).
Here the extra cost of ownership is limited while the manual tasks in question are better automated.
SAP MDG
MDG is the master data management offering from SAP. As such, this solution is very well suited for handling the master data that sits in the SAP ERP solution as it provides better capabilities around data governance, data quality and workflow management.
MDG comes with an extra cost of ownership compared to pure SAP ERP. An often-mentioned downside of MDG compared to other MDM platforms is that handling master data that sits outside SAP is cumbersome in SAP MDG.
Other MDM platforms
Most companies have master data outside SAP as well. Combined with that other MDM platforms may have capabilities better suited for them than SAP MDG and/or have a lower cost of ownership than SAP MDG. Therefore, we see that some organizations choose to handle also SAP master data in such platforms.
While MDO is quite close to SAP other MDM platforms, for example Informatica and Stibo STEP, have surprisingly very little ready-made capability and methodology for co-existing with SAP ERP.